- Mongo引擎教程
- MongoEngine - 主页
- MongoEngine——MongoDB
- MongoEngine - MongoDB 指南针
- MongoEngine - 对象文档映射器
- MongoEngine - 安装
- MongoEngine - 连接到 MongoDB 数据库
- MongoEngine - 文档类
- MongoEngine - 动态模式
- MongoEngine - 字段
- MongoEngine - 添加/删除文档
- MongoEngine - 查询数据库
- MongoEngine - 过滤器
- MongoEngine - 查询运算符
- MongoEngine - 查询集方法
- MongoEngine - 排序
- MongoEngine - 自定义查询集
- MongoEngine - 索引
- MongoEngine - 聚合
- MongoEngine - 高级查询
- MongoEngine - 文档继承
- MongoEngine - 原子更新
- MongoEngine-Javascript
- MongoEngine-GridFS
- MongoEngine - 信号
- MongoEngine - 文本搜索
- MongoEngine - 扩展
- MongoEngine 有用资源
- MongoEngine - 快速指南
- MongoEngine - 有用的资源
- MongoEngine - 讨论
MongoEngine - 快速指南
MongoEngine——MongoDB
NoSQL 数据库在过去十年中越来越受欢迎。在当今的实时 Web 应用程序世界中,移动和嵌入式设备正在生成大量数据。传统的关系型数据库(如Oracle、MySQL等)不适合字符串。此类数据的处理也很困难,因为它们具有固定和预定义的模式,并且不可扩展。NOSQL数据库具有灵活的模式,并以分布式方式存储在大量的社区服务器上。
NOSQL 数据库根据数据组织进行分类。MongoDB 是一种流行的文档存储 NOSQL 数据库。MongoDB 数据库的基本组成部分称为文档。文档是以 JSON 格式存储的键值对的集合。集合中存储了多个文档。集合可以被视为类似于任何关系数据库中的表,文档可以被视为表中的行。但是,应该注意的是,由于 MongoDB 是无模式的,集合的每个文档中的键值对数量不必相同。
MongoDB由MongoDB Inc.开发。它是一个通用的、基于分布式文档的数据库。它有企业版和社区版。适用于 Windows 操作系统的最新社区版本可以从https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2012plus-4.2.6-signed.msi下载。
在您选择的文件夹中安装 MongoDB,并使用以下命令启动服务器 -
D:\mongodb\bin>mongod
服务器现在已准备好在端口 27017 接收传入连接请求。MongoDB 数据库存储在 bin/data 目录中。可以通过上述命令中的 –dbpath 选项更改此位置。
在另一个命令终端中,使用以下命令启动 MongoDB 控制台 -
D:\mongodb\bin>mongo
MongoDB 提示符类似于我们通常在 MySQL 或 SQLite 终端中看到的提示符。所有数据库操作(例如创建数据库、插入文档、更新和删除以及检索文档)都可以在控制台内完成。
E:\mongodb\bin>mongo
MongoDB shell version v4.0.6
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("0d848b11-acf7-4d30-83df-242d1d7fa693") }
MongoDB server version: 4.0.6
---
>
使用的默认数据库是 test。
> db Test
使用“use”命令,任何其他数据库都会设置为当前数据库。如果指定的数据库不存在,则创建新的数据库。
> use mydb switched to db mydb
请参阅我们关于 MongoDB 的详细教程:https://www.tutorialspoint.com/mongodb/index.htm。
MongoEngine - MongoDB 指南针
MongoDB 还开发了一个 GUI 工具来处理 MongoDB 数据库。它被称为 MongoDB Compass。它是一个方便的工具,无需手动编写查询即可执行所有 CRUD 操作。它有助于许多活动,例如索引、文档验证等。
从https://www.mongodb.com/download-center/compass下载社区版 MongoDB Compass并启动MongoDBCompassCommunity.exe(在启动 Compass 之前确保 MongoDB 服务器正在运行)。通过提供正确的主机和端口号连接到本地服务器。
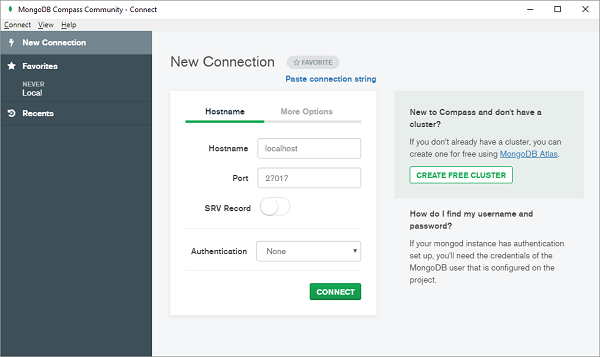
当前可用的所有数据库将列出如下 -
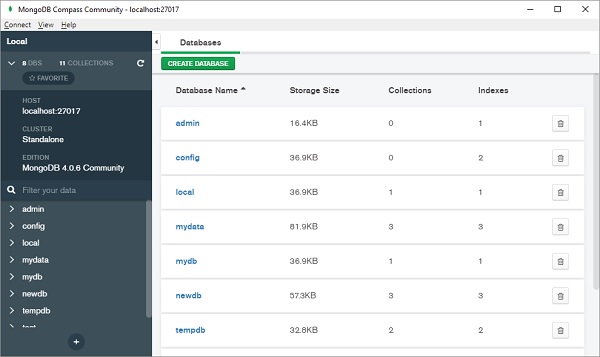
单击+按钮(显示在左面板底部)创建新数据库。
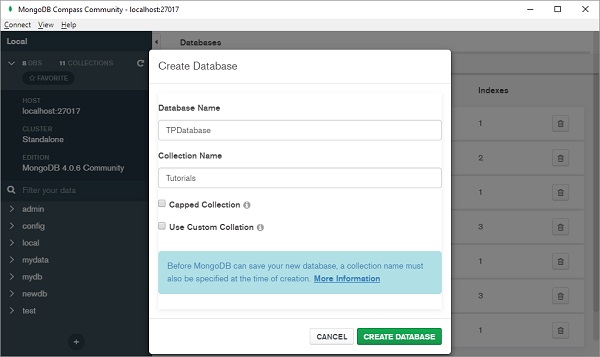
从列表中选择数据库名称并选择一个集合,如下所示 -
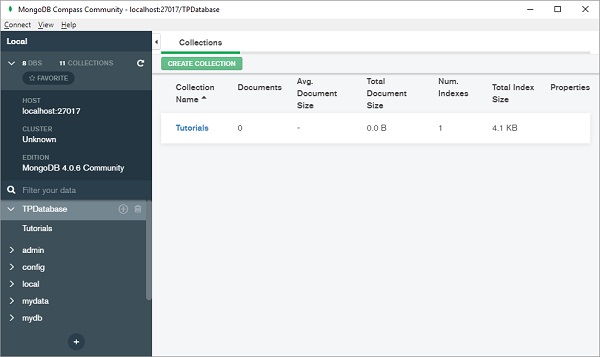
您可以直接添加文档或从 CSV 或 JSON 文件导入。
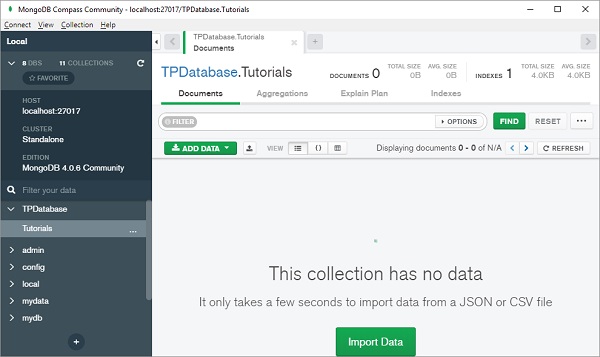
从“添加数据”下拉列表中选择“插入文档”。
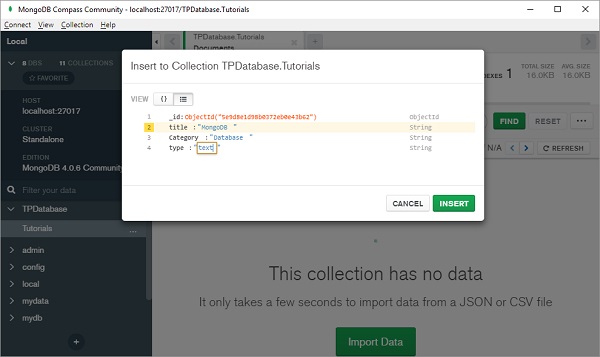
添加的文档将以 JSON、列表或表格形式显示 -
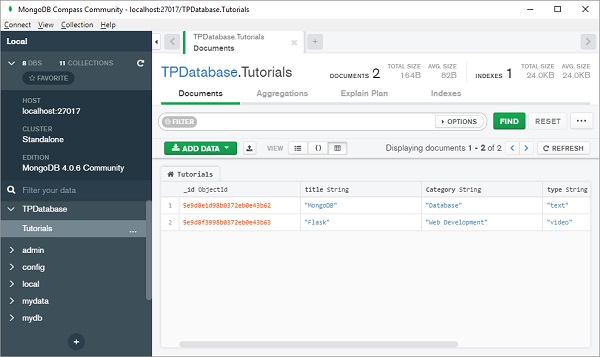
请注意,就像关系数据库中的表有一个主键一样,MongoDB 数据库中的文档有一个自动生成的名为“ _id ”的特殊键。
MongoDB Inc. 提供了用于连接 MongoDB 数据库的 Python 驱动程序。它称为PyMongo,其用法类似于标准 SQL 查询。
安装 PyMongo 模块后,我们需要 MongoClient 类的对象来与 MongoDB 服务器交互。
<<< from pymongo import MongoClient <<< client=MongoClient()
使用以下语句创建新数据库 -
db=client.mydatabase
该数据库上的 CRUD 操作是通过 insert_one() (或 insert_many())、find()、update() 和 delete() 等方法执行的。PyMongo 库的详细讨论可参见https://www.tutorialspoint.com/python_data_access/python_mongodb_introduction.htm。
然而,Python的用户定义对象不能存储在数据库中,除非转换为MongoDB的数据类型。这就是我们需要MongoEngine库的地方。
MongoEngine - 对象文档映射器
MongoDB 是一个基于文档的数据库。每个文档都是类似 JSON 的字段和值表示。MongoDB 中的文档大致相当于 RDBMS 表中的一行(MongoDB 相当于表是 Collection)。尽管 MongoDB 不强制执行任何预定义模式,但文档中的字段对象具有特定的数据类型。MongoDB 数据类型与 Python 的主要数据类型非常相似。如果必须存储 Python 用户定义类的对象,则必须手动将其属性解析为等效的 MongoDB 数据类型。
MongoEngine 在 PyMongo 上提供了一个方便的抽象层,并将 Document 类的每个对象映射到 MongoDB 数据库中的文档。MongoEngine API由Hary Marr于2013年8月开发。MongoEngine的最新版本是0.19.1。
MongoEngine 之于 MongoDB 就像 SQLAlchemy 之于 RDBMS 数据库。MongoEngine 库提供了一个 Document 类,用作定义自定义类的基础。该类的属性构成了 MongoDB 文档的字段。Document 类定义了执行 CRUD 操作的方法。在后续主题中,我们将学习如何使用它们。
MongoEngine - 安装
要使用 MongoEngine,您需要已经安装了 MongoDB,并且 MongoDB 服务器应该按照前面所述运行。
安装 MongoEngine 最简单的方法是使用 PIP 安装程序。
pip install mongoengine
如果您的Python安装没有安装Setuptools,您必须从https://github.com/MongoEngine/mongoengine下载MongoEngine并运行以下命令 -
python setup.py install
MongoEngine 有以下依赖项 -
pymongo>=3.4
六>=1.10.0
dateutil>=2.1.0
Pillow>=2.0.0
要验证安装是否正确,请运行导入命令并检查版本,如下所示 -
>>> import mongoengine >>> mongoengine.__version__ '0.19.1'
连接到 MongoDB 数据库
如前所述,您应该首先使用 mongod 命令启动 MongoDB 服务器。
MongoEngine 提供 connect() 函数来连接到正在运行的 mongodb 服务器实例。
从 mongoengine 导入连接 连接('mydata.db')
默认情况下,MongoDB 服务器在本地主机和端口 27017 上运行。要进行自定义,您应该为 connect() 提供主机和端口参数 -
连接('mydata.db',主机='192.168.1.1',端口=12345)
如果数据库需要身份验证,则应提供其凭据,例如用户名、密码和authentication_source 参数。
连接('mydata.db',用户名='user1',密码='***',authentication_source='admin')
MongoEngine 还支持 URI 样式连接而不是 IP 地址。
连接('mydata.db',host='mongodb://localhost/database_name')
connect() 函数还有另一个可选参数,称为replicaset。MongoDB 是一个分布式数据库。存储在一台服务器中的数据通常会复制到许多服务器实例中,以确保高可用性。MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。副本集是所有生产部署的基础。
连接(主机='mongodb://localhost/dbname?replicaSet=rs-name')
以下副本集方法定义如下:
| rs.add() | 将成员添加到副本集。 |
| rs.conf() | 返回副本集配置文档。 |
| rs.freeze() | 防止当前成员在一段时间内寻求当选为主要成员。 |
| rs.initiate() | 初始化一个新的副本集。 |
| rs.reconfig() | 通过应用新的副本集配置对象来重新配置副本集。 |
| rs.remove() | 从副本集中删除成员。 |
MongoEngine还允许连接多个数据库。您需要为每个数据库提供唯一的别名。例如,以下代码将 Python 脚本连接到两个 MongoDB 数据库。
connect(alias='db1', db='db1.db') connect(alias='db2', db='db2.db')
MongoEngine - 文档类
MongoEngine 被称为 ODM(对象文档映射器)。MongoEngine 定义了一个 Document 类。这是一个基类,其继承类用于定义存储在 MongoDB 数据库中的文档集合的结构和属性。该子类的每个对象在数据库中形成集合中的文档。
此 Document 子类中的属性是各种 Field 类的对象。以下是典型文档类的示例 -
from mongoengine import *
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
age = IntField()
def _init__(self, id, name, age):
self.studentid=id,
self.name=name
self.age=age
这看起来类似于 SQLAlchemy ORM 中的模型类。默认情况下,数据库中Collection的名称是Python类的名称,并将其名称转换为小写。但是,可以在 Document 类的元属性中指定不同的集合名称。
meta={collection': 'student_collection'}
现在声明此类的对象并调用 save() 方法将文档存储在数据库中。
s1=Student('A001', 'Tara', 20)
s1.save()
MongoEngine - 动态模式
MongoDB 数据库的优点之一是它支持动态模式。要创建支持动态架构的类,请将其从 DynamicDocument 基类创建子类。以下是具有动态模式的 Student 类 -
>>> class student(DynamicDocument): ... name=StringField()
第一步是像以前一样添加第一个文档。
>>> s1=student()
>>> s1.name="Tara"
>>> connect('mydb')
>>> s1.save()
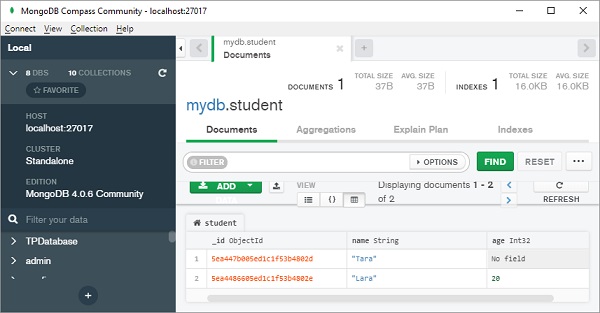
现在向第二个文档添加另一个属性并保存。
>>> s2=student() >>> setattr(s2,'age',20) >>> s2.name='Lara' >>> s2.save()
在数据库中,学生集合将显示两个具有动态模式的文档。
文档类的元字典可以通过指定 max_documents 和 max_size 来使用 Capped Collection。
max_documents - 允许存储在集合中的最大文档数。
max_size - 集合的最大大小(以字节为单位)。max_size 之前由 MongoDB 内部和 mongoengine 向上舍入为 256 的下一个倍数。
如果未指定 max_size 而指定了 max_documents,则 max_size 默认为 10485760 字节 (10MB)。
Document 类的其他参数列出如下 -
| 物体 | 在访问时延迟创建的 QuerySet 对象。 |
| 级联保存() | 递归保存文档上的所有引用和通用引用。 |
| 干净的() | 用于在运行验证之前进行文档级数据清理的挂钩。 |
| 创建索引() | 如果需要,创建给定的索引。 |
| drop_collection() | 从数据库中删除与此文档类型关联的整个集合。 |
| from_json() | 将 json 数据转换为 Document 实例。 |
| 调整() | 对数据库中的文档执行Atomics更新,并使用更新后的版本重新加载文档对象。 |
| PK | 获取主键。 |
| 节省() | 将文档保存到数据库。如果文档已经存在,则更新该文档,否则创建该文档。返回保存的对象实例。 |
| 删除() | 从数据库中删除当前文档。 |
| 插入() | 执行批量插入操作。 |
MongoEngine - 字段
MongoEngine 文档类具有一个或多个属性。每个属性都是 Field 类的一个对象。BaseField 是基类或所有字段类型。BaseField 类构造函数具有以下参数 -
BaseField(db_field,必填,默认,唯一,主键)
db_field表示数据库字段的名称。
required 参数决定该字段的值是否为必填项,默认为 false。
默认参数包含该字段的默认值
unique参数默认为 false 。如果您希望此字段对于每个文档都具有唯一值,则设置为 true。
Primary_key参数默认为 false 。True 使该字段成为主键。
有许多从 BaseField 派生的 Field 类。
数字字段
IntField(32 位整数)、LongField(64 位整数)、FloatField(浮点数)字段构造函数具有 min_value 和 max_value 参数。
还有DecimalField类。该字段对象的值是一个浮点数,其精度可以指定。以下参数是为 DecimalField 类定义的 -
DecimalField(最小值、最大值、force_string、精度、舍入)
| 最小值 | 指定最小可接受值 |
| 最大值 | 指定字段可以具有的最大值 |
| 强制字符串 | 如果为 True,则该字段的值存储为字符串 |
| 精确 | 将浮动表示形式限制为位数 |
| 四舍五入 | 根据以下预定义常量对数字进行舍入:decimal.ROUND_CEILING(向无穷大)decimal.ROUND_DOWN(向零)decimal.ROUND_FLOOR(向-无穷大)decimal.ROUND_HALF_DOWN(向最接近的关系趋向零)decimal.ROUND_HALF_EVEN(向最接近的关系)到最接近的偶数)decimal.ROUND_HALF_UP(到最接近的且远离零的关系)decimal.ROUND_UP(远离零)decimal.ROUND_05UP(如果四舍五入到零后的最后一位数字是0或5,则远离零;否则朝向零) |
文本字段
StringField 对象可以存储任何 Unicode 值。您可以在构造函数中指定字符串的 min_length 和 max_length。URLField对象是一个 StringField,能够将输入验证为 URL。EmailField验证字符串是否为有效的电子邮件表示形式。
StringField(max-length, min_length) URLField(url_regex) EmailField(domain_whiltelist, allow_utf8_user, allow_ip_domain)
domain_whitelist 参数包含您不支持的无效域的列表。如果设置为 True,allow_utf8_user 参数允许字符串包含 UTF8 字符作为电子邮件的一部分。allowed_ip_domain 参数默认为 false,但如果为 true,则可以是有效的 IPV4 或 IPV6 地址。
以下示例使用数字和字符串字段 -
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField()
age=IntField(min_value=6, max-value=20)
percent=DecimalField(precision=2)
email=EmailField()
s1=Student()
s1.studentid='001'
s1.name='Mohan Lal'
s1.age=20
s1.percent=75
s1.email='mohanlal@gmail.com'
s1.save()
执行上述代码时,学生集合显示如下文档 -

列表字段
这种类型的字段包装任何标准字段,从而允许将多个对象用作数据库中的列表对象。该字段可以与ReferenceField一起使用来实现一对多关系。
上面示例中的学生文档类修改如下 -
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
subjects = ListField(StringField())
s1=Student()
s1.studentid='A001'
s1.name='Mohan Lal'
s1.subjects=['phy', 'che', 'maths']
s1.save()
添加的文档以 JSON 格式显示,如下 -
{
"_id":{"$oid":"5ea6a1f4d8d48409f9640319"},
"studentid":"A001",
"name":"Mohan Lal",
"subjects":["phy","che","maths"]
}
字典域
DictField 类的对象存储一个Python 字典对象。这也将存储在相应的数据库字段中。
我们将上面示例中的 ListField 的类型更改为 DictField。
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
subjects = DictField()
s1=Student()
s1.studentid='A001'
s1.name='Mohan Lal'
s1.subjects['phy']=60
s1.subjects['che']=70
s1.subjects['maths']=80
s1.save()
数据库中的文档显示如下 -
{
"_id":{"$oid":"5ea6cfbe1788374c81ccaacb"},
"studentid":"A001",
"name":"Mohan Lal",
"subjects":{"phy":{"$numberInt":"60"},
"che":{"$numberInt":"70"},
"maths":{"$numberInt":"80"}
}
}
参考字段
MongoDB 文档可以使用此类字段存储对另一个文档的引用。这样,我们就可以像 RDBMS 中那样实现 join。ReferenceField 构造函数使用其他文档类的名称作为参数。
class doc1(Document): field1=StringField() class doc2(Document): field1=StringField() field2=ReferenceField(doc1)
在以下示例中,StudentDB 数据库包含两个文档类:学生和教师。学生类的文档包含对教师类对象的引用。
from mongoengine import *
connect('studentDB')
class Teacher (Document):
tid=StringField(required=True)
name=StringField()
class Student(Document):
sid = StringField(required=True)
name = StringField()
tid=ReferenceField(Teacher)
t1=Teacher()
t1.tid='T1'
t1.name='Murthy'
t1.save()
s1=Student()
s1.sid='S1'
s1.name='Mohan'
s1.tid=t1
s1.save()
运行上面的代码并在 Compass GUI 中验证结果。在 StudentDB 数据库中创建对应于两个文档类的两个集合。
添加的教师文档如下 -
{
"_id":{"$oid":"5ead627463976ea5159f3081"},
"tid":"T1",
"name":"Murthy"
}
学生文件显示内容如下 -
{
"_id":{"$oid":"5ead627463976ea5159f3082"},
"sid":"S1",
"name":"Mohan",
"tid":{"$oid":"5ead627463976ea5159f3081"}
}
请注意,Student 文档中的 ReferenceField 存储了相应 Teacher 文档的 _id。当访问时,Student 对象会自动转换为引用,并在访问相应的 Teacher 对象时取消引用。
要添加对正在定义的文档的引用,请使用“self”而不是其他文档类作为 ReferenceField 的参数。可能会注意到,就文档检索而言,使用 ReferenceField 可能会导致性能不佳。
ReferenceField 构造函数还有一个可选参数:reverse_delete_rule。它的值决定了当引用的文档被删除时要做什么。
可能的值如下 -
DO_NOTHING (0) - 不执行任何操作(默认)。
NULLIFY (1) - 将引用更新为 null。
CASCADE (2) - 删除与参考相关的文档。
DENY (3) - 阻止删除引用对象。
PULL (4) - 从引用列表字段中拉出引用
您可以使用引用列表实现一对多关系。假设学生文档必须与一个或多个教师文档相关,则 Student 类必须具有 ReferenceField 实例的 ListField。
从 mongoengine 导入 * 连接('studentDB') 班主任(文件): tid=StringField(必需=True) 名称=字符串字段() 班级学生(文件): sid = StringField(必需=True) 名称 = 字符串字段() tid=ListField(ReferenceField(老师)) t1=老师() t1.tid='T1' t1.name='穆蒂' t1.保存() t2=老师() t2.tid='T2' t2.name='萨克塞纳' t2.保存() s1=学生() s1.sid='S1' s1.name='莫罕' s1.tid=[t1,t2] s1.save()
在 Compass 中验证上述代码的结果时,您会发现学生文档引用了两个教师文档 -
教师收藏
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e4"},
"tid":"T1","name":"Murthy"
}
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e5"},
"tid":"T2","name":"萨克塞纳"
}
学生收藏
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e6"},
"sid":"S1","name":"莫罕",
"tid":[{"$oid":"5eaebcb61ae527e0db6d15e4"},{"$oid":"5eaebcb61ae527e0db6d15e5"}]
}
日期时间字段
DateTimeField 类的实例允许 MongoDB 数据库中的日期格式的数据。MongoEngine 寻找 Python-DateUtil 库来解析适当日期格式的数据。如果当前安装中不可用,则使用内置时间模块的 time.strptime() 函数表示日期。该类型字段的默认值是当前日期时间实例。
动态场
该字段可以处理不同类型的数据。这种类型的字段由DynamicDocument类内部使用。
图像场
这种类型的字段对应于文档中可以存储图像文件的字段。此类的构造函数可以接受 size 和thumbnail_size 参数(均以像素大小表示)。
MongoEngine - 添加/删除文档
我们已经使用 Document 类的 save() 方法在集合中添加文档。save() 方法可以借助以下参数进一步自定义 -
| 强制插入 | 默认值为 False,如果设置为 True 则不允许更新现有文档。 |
| 证实 | 验证文件;设置为 False 以跳过。 |
| 干净的 | 调用文档清理方法,验证参数应为 True。 |
| 写关注 | 将用作生成的 getLastError 命令的选项。例如,save(..., write_concern={w: 2, fsync: True}, ...) 将等待,直到至少两个服务器记录了写入,并将在主服务器上强制进行 fsync。 |
| 级联 | 设置级联保存的标志。您可以通过在文档 __meta__ 中设置“cascade”来设置默认值。 |
| 级联_kwargs | 要传递的可选关键字参数抛出到级联保存。相当于级联=True。 |
| _refs | 级联保存中使用的已处理引用的列表 |
| 保存条件 | 仅当数据库中的匹配记录满足条件时才执行保存。如果不满足条件则引发操作错误 |
| 信号_kwargs | 要传递给信号调用的 kwargs 字典。 |
您可以在调用 save() 之前设置用于验证文档的清理规则。通过提供自定义clean()方法,您可以进行任何预验证/数据清理。
class MyDocument(Document):
...
...
def clean(self):
if <condition>==True:
msg = 'error message.'
raise ValidationError(msg)
请注意,仅当验证打开且调用 save() 时才会调用 Cleaning。
Document 类还具有insert()方法来执行批量插入。它有以下参数 -
| 文档或文档 | 要插入的文档或文档列表 |
| 批量加载 | 如果为 True,则返回文档实例的列表 |
| 写关注 | 额外的关键字参数被传递给 insert() ,它将用作结果 getLastError 命令的选项。 |
| 信号_kwargs | (可选)要传递给信号调用的 kwargs 字典 |
如果文档包含任何 ReferenceField 对象,则默认情况下 save() 方法不会保存对这些对象的任何更改。如果您还希望保存所有引用,请注意每个保存都是一个单独的查询,然后将cascade 作为 True 传递给 save 方法将级联任何保存。
通过调用delete() 方法,从文档集合中删除文档非常简单。请记住,只有先前保存过文档,它才会生效。delete() 方法有以下参数 -
| 信号_kwargs | (可选)要传递给信号调用的 kwargs 字典。 |
| 写关注 | 额外的关键字参数被向下传递,这些参数将用作生成的 getLastError 命令的选项。 |
要从数据库中删除整个集合,请使用drop_collection()方法。它从数据库中删除与此文档类型关联的整个集合。如果文档没有集合集(如果它是抽象的,则该方法会引发OperationError)。
文档类中的modify ()方法对数据库中的文档执行Atomics更新并重新加载其更新版本。如果文档已更新,则返回 True;如果数据库中的文档与查询不匹配,则返回 False。请注意,如果该方法返回 True,则对文档所做的所有未保存的更改都将被拒绝。
参数
| 询问 | 仅当数据库中的文档与查询匹配时才会执行更新 |
| 更新 | Django 风格的更新关键字参数 |
MongoEngine - 查询数据库
connect() 函数返回一个 MongoClient 对象。使用该对象可用的list_database_names()方法,我们可以检索服务器上的数据库数量。
from mongoengine import *
con=connect('newdb')
dbs=con.list_database_names()
for db in dbs:
print (db)
还可以使用 list_collection_names() 方法获取数据库中的集合列表。
collections=con['newdb'].list_collection_names() for collection in collections: print (collection)
如前所述,Document 类具有对象属性,可以访问与数据库关联的对象。
newdb 数据库有一个与下面的 Document 类相对应的产品集合。为了获取所有文档,我们使用对象属性,如下所示 -
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
Name=StringField()
price=IntField()
for product in products.objects:
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 2 Name: TV Price: 50000 ID: 3 Name: Router Price: 2000 ID: 4 Name: Scanner Price: 5000 ID: 5 Name: Printer Price: 12500
MongoEngine - 过滤器
对象属性是一个查询集管理器。它在访问时创建并返回一个 QuerySet。可以借助字段名称作为关键字参数来对查询进行过滤。例如,在上面的产品集合中,要打印产品名称为“TV”的文档的详细信息,我们使用 Name 作为关键字参数。
for product in products.objects(Name='TV'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
您可以使用 QuerySet 对象的 filter 方法将过滤器应用于查询。以下代码片段还返回 name='TV' 的产品详细信息。
qset=products.objects
for product in qset.filter(Name='TV'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
MongoEngine - 查询运算符
除了用于检查相等性的 = 运算符之外,MongoEngine 中还定义了以下逻辑运算符。
| 讷 | 不等于 |
| 其 | 少于 |
| LTE | 小于或等于 |
| GT | 比...更棒 |
| 通用电气 | 大于或等于 |
| 不是 | 否定标准检查,可以在其他运算符之前使用 |
| 在 | 值在列表中 |
| 宁 | 值不在列表中 |
| 模组 | value % x == y,其中 x 和 y 是两个提供的值 |
| 全部 | 提供的值列表中的每个项目都在数组中 |
| 尺寸 | 数组的大小是 |
| 存在 | 字段值存在 |
这些运算符必须附加到带有双下划线 __ 的字段名称。
要使用大于 (gt) 运算符,请使用以下格式 -
#using greater than operator
for product in products.objects(price__gt=10000):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 2 Name: TV Price: 50000 ID: 5 Name: Printer Price: 12500
in 运算符类似于 Python 的 in 运算符。对于与列表中的名称匹配的产品名称,使用以下代码 -
for product in products.objects(Name__in=['TV', 'Printer']):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 2 Name: TV Price: 50000 ID: 5 Name: Printer Price: 12500
您可以使用以下运算符作为正则表达式的快捷方式,以将过滤器应用于查询 -
| 精确的 | 字符串字段与值完全匹配 |
| 精确的 | 字符串字段与值完全匹配(不区分大小写) |
| 包含 | 字符串字段包含值 |
| 图标包含 | 字符串字段包含值(不区分大小写) |
| 以。。开始 | 字符串字段以值开头 |
| 开始于 | 字符串字段以值开头(不区分大小写) |
| 以。。结束 | 字符串字段以值结尾 |
| 朋友 | 字符串字段以值结尾(不区分大小写) |
| 匹配 | 执行 $elemMatch 以便您可以匹配数组中的整个文档 |
例如,以下代码打印名称中包含“o”的名称的产品详细信息 -
for product in products.objects(Name__contains='o'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 3 Name: Router Price: 2000
在字符串查询的另一个示例中,以下代码显示以“er”结尾的名称 -
for product in products.objects(Name__endswith='er'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 3 Name: Router Price: 2000 ID: 4 Name: Scanner Price: 5000 ID: 5 Name: Printer Price: 12500
MongoEngine - 查询集方法
QuerySet 对象拥有以下用于查询数据库的有用方法。
第一的()
返回满足查询的第一个文档。以下代码将返回产品集合中价格 < 20000 的第一个文档。
qset=products.objects(price__lt=20000)
doc=qset.first()
print ('Name:',doc.Name, 'Price:',doc.price)
输出
Name: Router Price: 2000
排除()
这将导致提到的字段从查询集中排除。这里,Document类的to_json()方法用于获取Document的JSON化版本。ProductID 字段不会出现在结果中。
for product in products.objects.exclude('ProductID'):
print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "Name": "Laptop", "price": 25000}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "Name": "TV", "price": 50000}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "Name": "Router", "price": 2000}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "Name": "Scanner", "price": 5000}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "Name": "Printer", "price": 12500}
字段()
使用此方法可以操作要在查询集中加载哪些字段。使用字段名称作为关键字参数,并设置为 1 表示包含,0 表示排除。
for product in products.objects.fields(ProductID=1,price=1): print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "ProductID": 1, "price": 25000}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "ProductID": 2, "price": 50000}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "ProductID": 3, "price": 2000}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "ProductID": 4, "price": 5000}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "ProductID": 5, "price": 12500}
在 fields() 方法中将字段关键字参数设置为 0 的工作方式与 except() 方法类似。
for product in products.objects.fields(price=0): print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "ProductID": 1, "Name": "Laptop"}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "ProductID": 2, "Name": "TV"}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "ProductID": 3, "Name": "Router"}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "ProductID": 4, "Name": "Scanner"}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "ProductID": 5, "Name": "Printer"}
仅有的()
该方法的效果与 fields() 方法类似。仅与关键字参数对应的字段才会出现在查询集中。
for product in products.objects.only('Name'):
print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "Name": "Laptop"}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "Name": "TV"}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "Name": "Router"}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "Name": "Scanner"}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "Name": "Printer"}
和()
此方法计算查询集中给定字段的总和。
平均的()
该方法计算查询集中给定字段的平均值。
avg=products.objects.average('price')
ttl=products.objects.sum('price')
print ('sum of price field',ttl)
print ('average of price field',avg)
输出
sum of price field 94500 average of price field 18900.0
MongoEngine - 排序
QuerySet的order_by()函数用于以排序的方式获取查询结果。用法如下 -
Qset.order_by(‘fieldname’)
默认情况下,排序顺序为升序。对于降序排列,请在字段名称后附加 - 号。例如,要按升序获取价格明智的列表 -
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
for product in products.objects.order_by('price'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Router company:Iball price:2000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500 Name:Laptop company:Acer price:25000 Name:TV company:Philips price:31000 Name:Laptop company:Dell price:45000 Name:TV company:Samsung price:50000
以下代码将以名称降序获取列表 -
for product in products.objects.order_by('-Name'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:TV company:Samsung price:50000 Name:TV company:Philips price:31000 Name:Scanner company:Cannon price:5000 Name:Router company:Iball price:2000 Name:Printer company:Cannon price:12500 Name:Laptop company:Acer price:25000 Name:Laptop company:Dell price:45000
您还可以对多个字段进行排序。此代码将为您提供按公司升序排列的价目表。
for product in products.objects.order_by('company','price'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Laptop company:Acer price:25000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500 Name:Laptop company:Dell price:45000 Name:Router company:Iball price:2000 Name:TV company:Philips price:31000 Name:TV company:Samsung price:50000
MongoEngine - 自定义查询集
默认情况下,文档类上的对象属性返回一个查询集,而不应用任何过滤器。但是,您可以在修改查询集的文档上定义类方法。这样的方法应该接受两个参数 - doc_cls 和 queryset,并且需要用 queryset_manager() 进行修饰才能被识别。
@queryset_manager
def qry_method(docs_cls,queryset):
….
----
在下面的示例中,名为 products 的文档类具有一个 由 @queryset_manager 修饰的昂贵_prods() 方法。该方法本身对查询集应用过滤器,以便仅返回价格 >20000 的对象。此方法现在是默认文档查询,产品类的对象属性返回过滤后的文档。
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
@queryset_manager
def expensive_prods(docs_cls,queryset):
return queryset.filter(price__gt=20000)
for product in products.expensive_prods():
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Laptop company:Acer price:25000 Name:TV company:Samsung price:50000 Name:TV company:Philips price:31000 Name:Laptop company:Dell price:45000
如果您希望自定义过滤文档的方法,请首先声明 QuerySet 类的子类,并将其用作元字典中的 queryset_class 属性的值。
下面的示例使用 MyQuerySet 类作为自定义查询集的定义。此类中的 myqrymethod() 过滤名称字段以“er”结尾的文档。在products类中,meta属性指的是该queryset子类用作queryset_class属性的值。
from mongoengine import *
con=connect('newdb')
class MyQuerySet(QuerySet):
def myqrymethod(self):
return self.filter(Name__endswith='er')
class products (Document):
meta = {'queryset_class': MyQuerySet}
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
for product in products.objects.myqrymethod():
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Router company:Iball price:2000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500
MongoEngine - 索引
索引集合可以加快查询处理速度。默认情况下,每个集合都会自动在 _id 字段上建立索引。此外,您可以在一个或多个字段上创建索引。
使用Compass,我们可以非常轻松地建立索引。单击“索引”选项卡上的“创建索引”按钮,如下图所示 -
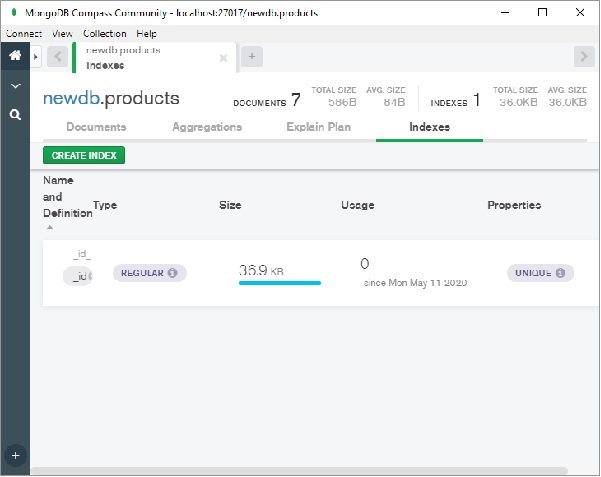
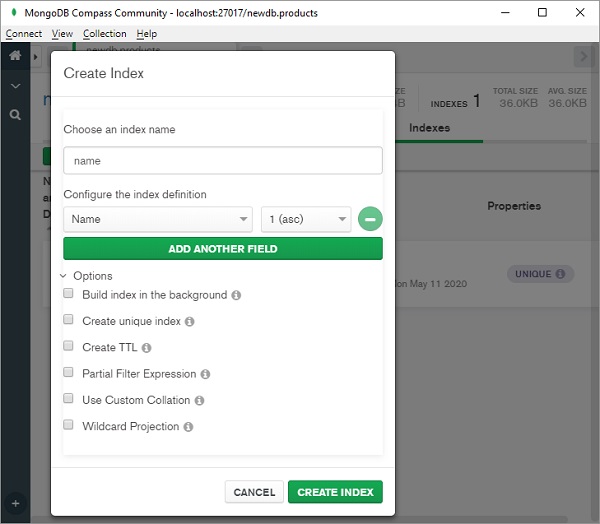
将出现一个对话框,如图所示。选择索引名称、要索引的字段、索引顺序(升序或降序)和其他选项。
使用 MongoEngine 时,通过在 Document 类定义的元字典中指定“indexes”键来创建索引。
Indexes 属性的值是字段列表。在下面的示例中,我们要求学生集合中的文档根据名称字段建立索引。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':['name']}
s1=student()
s1.name='Avinash'
s1.course='DataScience'
s1.save()
s2=student()
s2.name='Anita'
s2.course='WebDesign'
s2.save()
默认情况下,索引顺序为升序。可以通过在前面添加“+”(表示升序)或“-”(表示降序)来指定顺序。
要创建复合索引,请使用字段名称元组,可以选择附加 + 或 – 符号来指示排序顺序。
在下面的示例中,学生文档类包含名称和课程的复合索引的定义(注意 - 课程字段前面的符号,这意味着索引是按名称升序和按课程降序构建的。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[('name','-course')]}
s1=student()
s1.name='Avinash'
s1.course='DataScience'
s1.save()
s2=student()
s2.name='Anita'
s2.course='WebDesign'
s2.save()
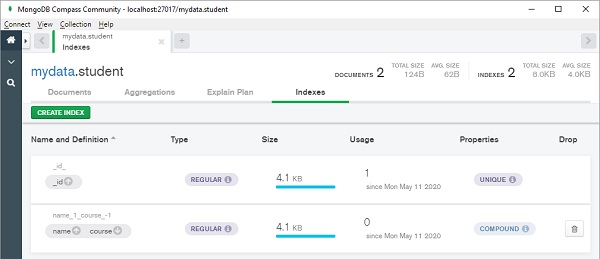
MongoDB Compass 将显示索引如下 -
“索引”的值可能是各种选项的字典,如下所示 -
| 领域 | 要索引的字段。 |
| CLS | 如果allow_inheritance打开,您可以配置索引是否应该自动添加_cls字段。 |
| 疏 | 索引是否应该稀疏。 |
| 独特的 | 索引是否应该是唯一的。 |
| 秒后过期 | 通过设置时间(以秒为单位)自动使集合中的数据过期 |
| 姓名 | 允许您指定索引的名称 |
| 整理 | 允许创建不区分大小写的索引 |
以下示例在名称字段上创建索引,该索引将在 3600 秒后过期。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[{
'fields': ['name'],
'expireAfterSeconds': 3600
}
]
}
要指定文本索引,请在字段名称前添加“$”符号,对于散列索引,请使用“#”作为前缀。
当文档添加到集合中时,会自动创建如此指定的索引。要禁用自动创建,请在元属性中将“ auto_create_index ”设置为 False。
我们有Document 类的list_indexes()方法,用于显示可用索引的列表。
print (student.list_indexes())
[[('name', 1)], [('_id', 1)]]
要在元字典中没有的字段上创建索引,请使用create_index()方法。以下代码将在课程字段上创建索引 -
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[{
'fields': ['name'],
'expireAfterSeconds': 3600
}
]}
student.create_index(['course'])
MongoEngine - 聚合
术语“聚合”用于处理数据并返回计算结果的操作。对集合中的一个或多个文档字段求和、计数和平均值可以称为聚合函数。
MongoEngine提供了aggregate()函数,封装了PyMongo的聚合框架。聚合操作使用集合作为输入并返回一个或多个文档作为结果。
MongoDB 使用数据处理管道的概念。一条管道可以有多个阶段。基本阶段提供了类似查询的过滤和操作。其他提供了按一个或多个字段进行分组和/或排序的工具、字符串连接任务、数组聚合工具等。
MongoDB 管道创建中定义了以下阶段 -
| 姓名 | 描述 |
|---|---|
| $项目 | 通过添加新字段或删除现有字段来重塑流中的每个文档。 |
| $匹配 | 过滤文档流以仅允许匹配的文档未经修改地传递到下一阶段。$match 使用标准 MongoDB 查询。 |
| $编辑 | 通过根据文档本身存储的信息限制每个文档的内容来重塑每个文档。 |
| $限额 | 限制不加修改地传递到管道的文档 |
| $跳过 | 跳过前 n 个文档,并将未修改的剩余文档传递到管道。 |
| $组 | 按给定标识符表达式对输入文档进行分组,并将累加器表达式应用于每个组。输出文档仅包含标识符字段和累积字段。 |
| $排序 | 按指定的排序键对文档流重新排序。 |
| $出 | 将聚合管道的结果文档写入集合。 |
聚合表达式使用字段路径来访问输入文档中的字段。要指定字段路径,请使用在字段名称前面加上美元符号 $$$ 前缀的字符串。表达式可以使用一个或多个布尔运算符($and、$or、$not)和比较运算符($eq、$gt、$lt、$gte、$lte 和 $ne)。
以下算术表达式也用于聚合 -
| $添加 | 添加数字以返回总和。接受任意数量的参数表达式 |
| $减去 | 返回第一个值减去第二个值的结果 |
| $乘 | 将数字相乘以返回乘积。接受任意数量的参数表达式 |
| $除法 | 返回第一个数字除以第二个数字的结果。接受两个参数表达式 |
| $mod | 返回第一个数字除以第二个数字的余数。接受两个参数表达式 |
以下字符串表达式也可以用于聚合 -
| $连接 | 连接任意数量的字符串 |
| $子字符串 | 返回字符串的子字符串,从指定索引位置开始直到指定长度 |
| 降低$ | 将字符串转换为小写。接受单个参数表达式 |
| $到上层 | 将字符串转换为大写。接受单个参数表达式 |
| $strcasecmp | 执行字符串比较,如果两个字符串相等则返回 0,如果第一个字符串大于第二个字符串则返回 1,如果第一个字符串小于第二个字符串则返回 -1 |
为了演示aggregate()函数在MongoEngine中的工作原理,我们首先定义一个名为orders的Document类。
from mongoengine import *
con=connect('mydata')
class orders(Document):
custID = StringField()
amount= IntField()
status = StringField()
然后我们在订单集合中添加以下文档 -
| _ID | 客户ID | 数量 | 地位 |
|---|---|---|---|
| 对象 ID("5eba52d975fa1e26d4ec01d0") | A123 | 500 | A |
| 对象 ID("5eba536775fa1e26d4ec01d1") | A123 | 250 | A |
| 对象 ID(“5eba53b575fa1e26d4ec01d2”) | B212 | 200 | D |
| 对象 ID("5eba540e75fa1e26d4ec01d3") | B212 | 400 | A |
仅当状态等于“A”时,aggregate() 函数才用于查找每个 custID 的金额字段总和。因此,管道构造如下。
管道的第一阶段使用 $match 来过滤 status='A' 的文档。第二阶段使用 $group 标识符对 CustID 上的文档进行分组并执行金额求和。
pipeline = [
{"$match" : {"status" : "A"}},
{"$group": {"_id": "$custID", "total": {"$sum": "$amount"}}}
]
该管道现在用作aggregate() 函数的参数。
docs = orders.objects().aggregate(pipeline)
我们可以使用 for 循环迭代文档光标。完整的代码如下 -
from mongoengine import *
con=connect('mydata')
class orders(Document):
custID = StringField()
amount= IntField()
status = StringField()
pipeline = [
{"$match" : {"status" : "A"}},
{"$group": {"_id": "$custID", "total": {"$sum": "$amount"}}}
]
docs = orders.objects().aggregate(pipeline)
for doc in docs:
print (x)
对于给定的数据,生成以下输出 -
{'_id': 'B212', 'total': 400}
{'_id': 'A123', 'total': 750}
MongoEngine - 高级查询
为了更高效地检索文档中的字段子集,请使用 Objects 属性的 only() 方法。这将显着提高性能,特别是对于长度极大的字段(例如 ListField)。将必填字段传递给 only() 函数。如果执行only()查询后访问其他字段,则返回默认值。
from mongoengine import *
con=connect('newdb')
class person (Document):
name=StringField(required=True)
city=StringField(default='Mumbai')
pin=IntField()
p1=person(name='Himanshu', city='Delhi', pin=110012).save()
doc=person.objects.only('name').first()
print ('name:',doc.name)
print ('city:', doc.city)
print ('PIN:', doc.pin)
输出
name: Himanshu city: Mumbai PIN: None
注意- 城市属性的值用作默认值。由于未指定 PIN 默认值,因此打印 None。
如果需要缺失字段,可以调用 reload() 函数。
当文档类具有 ListField 或 DictField 时,在迭代它时,任何 DBREf 对象都会自动取消引用。为了进一步提高效率,特别是在文档有ReferenceField的情况下,可以使用select_lated()函数来限制查询数量,该函数将QuerySet转换为列表并实现取消引用。
MongoEngine API 包含 Q 类,可用于构建由多个约束组成的高级查询。Q 表示查询的一部分,可以通过关键字参数语法和二进制 & 和 | 来初始化。运营商。
person.objects(Q(name__startswith=’H’) &Q(city=’Mumbai’))
MongoEngine - 文档继承
可以定义任何用户定义的 Document 类的继承类。如果需要,继承的类可以添加额外的字段。但是,由于此类不是 Document 类的直接子类,因此它不会创建新的集合,而是将其对象存储在其父类使用的集合中。在父类中,元属性' allow_inheritance下面的示例中,我们首先将employee定义为文档类并将allow_inheritance设置为true。工资等级源自employee,增加了两个字段dept和sal。Employee 对象以及工资类别存储在雇员集合中。
在下面的示例中,我们首先将employee定义为文档类并将allow_inheritance设置为true。工资等级源自employee,增加了两个字段dept和sal。Employee 对象以及工资类别存储在雇员集合中。
from mongoengine import *
con=connect('newdb')
class employee (Document):
name=StringField(required=True)
branch=StringField()
meta={'allow_inheritance':True}
class salary(employee):
dept=StringField()
sal=IntField()
e1=employee(name='Bharat', branch='Chennai').save()
s1=salary(name='Deep', branch='Hyderabad', dept='Accounts', sal=25000).save()
我们可以验证两个文档存储在员工集合中,如下所示 -
{
"_id":{"$oid":"5ebc34f44baa3752530b278a"},
"_cls":"employee",
"name":"Bharat",
"branch":"Chennai"
}
{
"_id":{"$oid":"5ebc34f44baa3752530b278b"},
"_cls":"employee.salary",
"name":"Deep",
"branch":"Hyderabad",
"dept":"Accounts",
"sal":{"$numberInt":"25000"}
}
请注意,为了识别相应的 Document 类,MongoEngine 添加了一个“_cls”字段并将其值设置为“employee”和“employee.salary”。
如果要向一组 Document 类提供额外的功能,但又不想产生继承开销,则可以首先创建一个抽象类,然后从该抽象类派生一个或多个类。要使类抽象,元属性“abstract”设置为 True。
from mongoengine import *
con=connect('newdb')
class shape (Document):
meta={'abstract':True}
def area(self):
pass
class rectangle(shape):
width=IntField()
height=IntField()
def area(self):
return self.width*self.height
r1=rectangle(width=20, height=30).save()
MongoEngine - Atomics更新
Atomics性是 ACID 事务属性之一。数据库事务必须是不可分割和不可简化的,以便它要么完全发生,要么根本不发生。这个属性称为Atomics性。MongoDB 仅支持单个文档的Atomics性,而不支持多文档事务。
MongoEngine 提供以下方法用于查询集的Atomics更新。
update_one() - 覆盖或添加与查询匹配的第一个文档。
update() - 对查询匹配的字段执行Atomics更新。
modify() - 更新文档并返回它。
这些方法可以使用以下修饰符。(这些修饰符位于字段之前,而不是之后)。
| 放 | 设置一个特定值 |
| 未设置 | 删除特定值 |
| 公司 | 将值增加给定量 |
| 十二月 | 将值减少给定量 |
| 推 | 将值附加到列表中 |
| 推送全部 | 将多个值附加到列表中 |
| 流行音乐 | 根据值删除列表的第一个或最后一个元素 |
| 拉 | 从列表中删除一个值 |
| 全部拉动 | 从列表中删除多个值 |
| 添加到集合 | 仅当列表中尚不存在时才将值添加到列表中 |
下面是一个Atomics更新的例子,我们首先创建一个名为tests的Document类,并在其中添加一个文档。
from mongoengine import *
con=connect('newdb')
class tests (Document):
name=StringField()
attempts=IntField()
scores=ListField(IntField())
t1=tests()
t1.name='XYZ'
t1.attempts=0
t1.scores=[]
t1.save()
让我们使用update_one()方法将名称字段从 XYZ 更新到 MongoDB。
tests.objects(name='XYZ').update_one(set__name='MongoDB')
Push 修饰符用于在 ListField(分数)中添加数据。
tests.objects(name='MongoDB').update_one(push__scores=50)
要将 attempts 字段加一,我们可以使用 inc 修饰符。
tests.objects(name='MongoDB').update_one(inc__attempts=1)
更新后的文档如下所示 -
{
"_id":{"$oid":"5ebcf8d353a48858e01ced04"},
"name":"MongoDB",
"attempts":{"$numberInt":"1"},
"scores":[{"$numberInt":"50"}]
}
MongoEngine-Javascript
MongoEngine 的 QuerySet 对象有exec_js()方法,允许在 MongoDB 服务器上执行 Javascript 函数。该函数处理以下参数 -
exec_js(code, *field_names, **options)
在哪里,
code - 包含要执行的 Javascript 代码的字符串
fields - 在你的函数中使用,它将作为参数传递
options - 您希望函数可用的选项(通过选项对象在 Javascript 中访问)
此外,还为函数的作用域提供了更多变量,如下所示 -
collection - 对应于 Document 类的集合的名称。这应该用于在 Javascript 代码中从数据库获取 Collection 对象。
query - QuerySet 对象生成的查询;传递到 Javascript 函数中 Collection 对象的 find() 方法。
options - 包含传递给 exec_js() 的关键字参数的对象。
请注意,MongoEngine 文档类中的属性可能在数据库中使用不同的名称(使用 Field 构造函数的 db_field 关键字参数进行设置)。