- HCatalog教程
- HCatalog - 主页
- HCatalog - 简介
- HCatalog - 安装
- HCatalog - CLI
- HCatalog CLI 命令
- HCatalog - 创建表
- HCatalog - 更改表
- HC 目录 - 查看
- HCatalog - 显示表格
- HCatalog - 显示分区
- HCatalog - 索引
- HCatalogAPIS
- HCatalog - 读者作家
- HCatalog - 输入输出格式
- HCatalog - 加载器和存储器
- HCatalog 有用资源
- HCatalog - 快速指南
- HCatalog - 有用的资源
- HCatalog - 讨论
HCatalog - 快速指南
HCatalog - 简介
什么是 HCatalog?
HCatalog是Hadoop的表存储管理工具。它将 Hive 元存储的表格数据公开给其他 Hadoop 应用程序。它使用户能够使用不同的数据处理工具(Pig、MapReduce)轻松地将数据写入网格。它确保用户不必担心数据存储在何处或以什么格式存储。
HCatalog 的工作方式类似于 Hive 的关键组件,它使用户能够以任何格式和任何结构存储数据。
为什么选择 HCatalog?
为正确的工作启用正确的工具
Hadoop 生态系统包含不同的数据处理工具,例如 Hive、Pig 和 MapReduce。尽管这些工具不需要元数据,但当元数据存在时,它们仍然可以从中受益。共享元数据存储还使用户能够跨工具更轻松地共享数据。使用 MapReduce 或 Pig 加载和规范化数据,然后通过 Hive 进行分析的工作流程非常常见。如果所有这些工具共享一个元存储,则每个工具的用户都可以立即访问使用另一工具创建的数据。无需加载或转移步骤。
捕获处理状态以实现共享
HCatalog 可以发布您的分析结果。因此其他程序员可以通过“REST”访问您的分析平台。您发布的模式对于其他数据科学家也很有用。其他数据科学家将您的发现用作后续发现的输入。
将 Hadoop 与一切集成
Hadoop 作为处理和存储环境为企业带来了很多机会;然而,为了推动采用,它必须与现有工具配合使用并增强现有工具。Hadoop 应该作为您的分析平台的输入,或者与您的运营数据存储和 Web 应用程序集成。组织应该享受 Hadoop 的价值,而无需学习全新的工具集。REST 服务通过熟悉的 API 和类似 SQL 的语言向企业开放平台。企业数据管理系统使用HCatalog与Hadoop平台更深入地集成。
HCatalog架构
下图展示了HCatalog的整体架构。
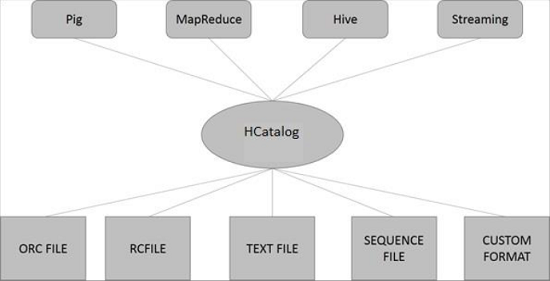
HCatalog 支持读取和写入可编写SerDe (串行器-解串器)的任何格式的文件。默认情况下,HCatalog 支持 RCFile、CSV、JSON、SequenceFile 和 ORC 文件格式。要使用自定义格式,您必须提供InputFormat、OutputFormat 和SerDe。
HCatalog 构建在 Hive 元存储之上,并合并了 Hive 的 DDL。HCatalog 为 Pig 和 MapReduce 提供读写接口,并使用 Hive 的命令行接口来发出数据定义和元数据探索命令。
HCatalog - 安装
Hive、Pig、HBase等Hadoop子项目均支持Linux操作系统。因此,您需要在系统上安装 Linux 版本。HCatalog于2013年3月26日与Hive安装合并。从Hive-0.11.0版本开始,HCatalog附带Hive安装。因此,请按照以下步骤安装 Hive,Hive 会自动在您的系统上安装 HCatalog。
第1步:验证JAVA安装
在安装 Hive 之前,必须在系统上安装 Java。您可以使用以下命令检查系统上是否已安装 Java -
$ java –version
如果您的系统上已经安装了 Java,您将看到以下响应 -
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统上没有安装 Java,则需要按照以下步骤操作。
第 2 步:安装 Java
通过访问以下链接下载 Java(JDK <最新版本> - X64.tar.gz):http://www.oracle.com/
然后jdk-7u71-linux-x64.tar.gz将下载到您的系统上。
通常,您会在“下载”文件夹中找到下载的 Java 文件。验证它并使用以下命令提取jdk-7u71-linux-x64.gz文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
要使 Java 对所有用户可用,您必须将其移动到位置“/usr/local/”。打开 root,然后键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
要设置PATH和JAVA_HOME变量,请将以下命令添加到~/.bashrc文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
现在,如上所述,从终端使用命令java -version验证安装。
步骤 3:验证 Hadoop 安装
在安装 Hive 之前,必须在系统上安装 Hadoop。让我们使用以下命令验证 Hadoop 安装 -
$ hadoop version
如果 Hadoop 已经安装在您的系统上,那么您将得到以下响应 -
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果您的系统上未安装 Hadoop,请继续执行以下步骤 -
第四步:下载Hadoop
使用以下命令从 Apache Software Foundation 下载并解压 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
第五步:伪分布式安装Hadoop
以下步骤用于以伪分布式方式安装Hadoop 2.4.1 。
设置 Hadoop
您可以通过将以下命令附加到~/.bashrc文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
Hadoop配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。您需要根据您的 Hadoop 基础设施对这些配置文件进行适当的更改。
$ cd $HADOOP_HOME/etc/hadoop
为了使用 Java 开发 Hadoop 程序,您必须通过将JAVA_HOME值替换为系统中 Java 的位置来重置hadoop-env.sh文件中的 Java 环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
下面给出了配置 Hadoop 时必须编辑的文件列表。
核心站点.xml
core -site.xml文件包含 Hadoop 实例使用的端口号、为文件系统分配的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并在 <configuration> 和 </configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs -site.xml文件包含本地文件系统的复制数据值、名称节点路径和数据节点路径等信息。它意味着您要存储 Hadoop 基础设施的地方。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
注意- 在上面的文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础设施进行更改。
纱线站点.xml
该文件用于将yarn配置到Hadoop中。打开yarn-site.xml 文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
该文件用于指定我们正在使用哪个 MapReduce 框架。默认情况下,Hadoop包含一个yarn-site.xml模板。首先,您需要使用以下命令将文件从mapred-site,xml.template复制到mapred-site.xml文件。
$ cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
第 6 步:验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
名称节点设置
使用命令“hdfs namenode -format”设置 namenode,如下所示 -
$ cd ~ $ hdfs namenode -format
预期结果如下 -
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
验证 Hadoop DFS
以下命令用于启动 DFS。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下 -
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
验证 Yarn 脚本
以下命令用于启动 Yarn 脚本。执行此命令将启动您的 Yarn 守护进程。
$ start-yarn.sh
预期输出如下 -
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/ yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
在浏览器上访问 Hadoop
访问 Hadoop 的默认端口号为 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
http://localhost:50070/
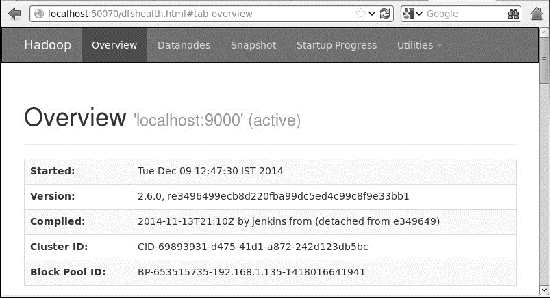
验证集群的所有应用程序
访问集群所有应用程序的默认端口号是8088。使用以下url访问该服务。
http://localhost:8088/
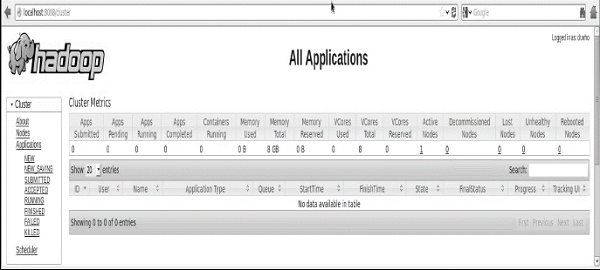
完成 Hadoop 安装后,继续下一步并在系统上安装 Hive。
第7步:下载Hive
我们在本教程中使用 hive-0.14.0。您可以通过访问以下链接下载它:http://apache.petsads.us/hive/hive-0.14.0/。让我们假设它被下载到/Downloads目录中。在这里,我们为本教程下载名为“ apache-hive-0.14.0-bin.tar.gz ”的 Hive 存档。以下命令用于验证下载 -
$ cd Downloads $ ls
下载成功后,您会看到以下响应 -
apache-hive-0.14.0-bin.tar.gz
第8步:安装Hive
在系统上安装 Hive 需要执行以下步骤。让我们假设 Hive 存档已下载到/Downloads目录中。
提取并验证 Hive 存档
以下命令用于验证下载并提取 Hive 存档 -
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
下载成功后,您会看到以下响应 -
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
将文件复制到/usr/local/hive目录
我们需要从超级用户“su -”复制文件。以下命令用于将解压目录中的文件复制到/usr/local/hive目录。
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
设置Hive环境
您可以通过将以下行附加到~/.bashrc文件来设置 Hive 环境 -
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
以下命令用于执行 ~/.bashrc 文件。
$ source ~/.bashrc
第9步:配置Hive
要使用 Hadoop 配置 Hive,您需要编辑hive-env.sh文件,该文件位于$HIVE_HOME/conf目录中。以下命令重定向到 Hive配置文件夹并复制模板文件 -
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
通过附加以下行来编辑hive-env.sh文件 -
export HADOOP_HOME=/usr/local/hadoop
至此,Hive安装完成。现在您需要外部数据库服务器来配置 Metastore。我们使用 Apache Derby 数据库。
第 10 步:下载并安装 Apache Derby
按照下面给出的步骤下载并安装 Apache Derby -
下载 Apache Derby
以下命令用于下载 Apache Derby。下载需要一些时间。
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
以下命令用于验证下载 -
$ ls
下载成功后,您会看到以下响应 -
db-derby-10.4.2.0-bin.tar.gz
提取并验证德比档案
以下命令用于提取和验证 Derby 存档 -
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
下载成功后,您会看到以下响应 -
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
将文件复制到 /usr/local/derby 目录
我们需要从超级用户“su -”复制。以下命令用于将文件从提取的目录复制到/usr/local/derby目录 -
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
设置德比的环境
您可以通过将以下行附加到~/.bashrc文件来设置 Derby 环境 -
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
以下命令用于执行~/.bashrc 文件-
$ source ~/.bashrc
为 Metastore 创建目录
在 $DERBY_HOME 目录中创建一个名为data的目录来存储 Metastore 数据。
$ mkdir $DERBY_HOME/data
Derby 安装和环境设置现已完成。
步骤11:配置Hive元存储
配置Metastore意味着指定Hive数据库的存储位置。您可以通过编辑$HIVE_HOME/conf目录中的hive-site.xml文件来完成此操作。首先,使用以下命令复制模板文件 -
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
编辑hive-site.xml并在 <configuration> 和 </configuration> 标记之间附加以下行 -
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby://localhost:1527/metastore_db;create = true</value> <description>JDBC connect string for a JDBC metastore</description> </property>
创建一个名为jpox.properties的文件并将以下行添加到其中 -
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
第12步:验证Hive安装
在运行 Hive 之前,您需要在 HDFS 中创建/tmp文件夹和单独的 Hive 文件夹。在这里,我们使用/user/hive/warehouse文件夹。您需要为这些新创建的文件夹设置写入权限,如下所示 -
chmod g+w
现在在验证 Hive 之前将它们设置在 HDFS 中。使用以下命令 -
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
以下命令用于验证 Hive 安装 -
$ cd $HIVE_HOME $ bin/hive
成功安装 Hive 后,您会看到以下响应 -
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/ hive-log4j.properties Hive history =/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
您可以执行以下示例命令来显示所有表 -
hive> show tables; OK Time taken: 2.798 seconds hive>
步骤 13:验证 HCatalog 安装
使用以下命令为 HCatalog Home 设置系统变量HCAT_HOME。
export HCAT_HOME = $HiVE_HOME/HCatalog
使用以下命令验证 HCatalog 安装。
cd $HCAT_HOME/bin ./hcat
如果安装成功,您将看到以下输出 -
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
HCatalog - CLI
可以从命令$HIVE_HOME/HCatalog/bin/hcat调用 HCatalog 命令行界面 (CLI) ,其中 $HIVE_HOME 是 Hive 的主目录。hcat是用于初始化 HCatalog 服务器的命令。
使用以下命令初始化 HCatalog 命令行。
cd $HCAT_HOME/bin ./hcat
如果安装正确完成,那么您将得到以下输出 -
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
HCatalog CLI 支持这些命令行选项 -
| 先生编号 | 选项 | 示例和描述 |
|---|---|---|
| 1 | -G | hcat -g 我的组 ... 要创建的表必须具有组“mygroup”。 |
| 2 | -p | hcat -p rwxr-xr-x ... 创建的表必须具有读、写、执行权限。 |
| 3 | -F | hcat -f myscript.HCatalog ... myscript.HCatalog 是一个包含要执行的 DDL 命令的脚本文件。 |
| 4 | -e | hcat -e '创建表 mytable(a int);' ... 将以下字符串视为 DDL 命令并执行它。 |
| 5 | -D | hcat -Dkey = 值... 将键值对作为 Java 系统属性传递给 HCatalog。 |
| 6 | - | 猫 打印使用信息。 |
注意 -
-g和-p选项不是强制性的。
可以同时提供-e或-f选项,但不能同时提供两者。
选项的顺序并不重要;您可以按任意顺序指定选项。
| 先生编号 | DDL命令及说明 |
|---|---|
| 1 | 创建表 使用 HCatalog 创建表。如果您使用 CLUSTERED BY 子句创建表,您将无法使用 Pig 或 MapReduce 对其进行写入。 |
| 2 | 修改表 除 REBUILD 和 CONCATENATE 选项外均受支持。其Behave与 Hive 中的Behave相同。 |
| 3 | 掉落表 支持的。Behave与 Hive 相同(删除完整的表和结构)。 |
| 4 | 创建/更改/删除视图 支持的。Behave与 Hive 相同。 注意- Pig 和 MapReduce 无法读取或写入视图。 |
| 5 | 显示表格 显示表的列表。 |
| 6 | 显示分区 显示分区列表。 |
| 7 | 创建/删除索引 支持 CREATE 和 DROP FUNCTION 操作,但创建的函数仍必须在 Pig 中注册并放置在 MapReduce 的 CLASSPATH 中。 |
| 8 | 描述 支持的。Behave与 Hive 相同。描述结构。 |
上表中的一些命令将在后续章节中进行解释。
HCatalog - 创建表
本章介绍如何创建表以及如何向其中插入数据。在 HCatalog 中创建表的约定与使用 Hive 创建表非常相似。
创建表语句
Create Table 是用于使用 HCatalog 在 Hive Metastore 中创建表的语句。其语法和示例如下 -
句法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
例子
让我们假设您需要使用CREATE TABLE语句创建一个名为employee的表。下表列出了员工表中的字段及其数据类型-
| 先生编号 | 字段名称 | 数据类型 |
|---|---|---|
| 1 | 开斋节 | 整数 |
| 2 | 姓名 | 细绳 |
| 3 | 薪水 | 漂浮 |
| 4 | 指定 | 细绳 |
以下数据定义了受支持的字段(例如注释)、行格式字段(例如字段终止符、行终止符和存储文件类型)。
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
以下查询使用上述数据创建一个名为employee的表。
./hcat –e "CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) \ COMMENT 'Employee details' \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY ‘\t’ \ LINES TERMINATED BY ‘\n’ \ STORED AS TEXTFILE;"
如果添加选项IF NOT EXISTS,HCatalog 会在表已存在的情况下忽略该语句。
成功创建表后,您将看到以下响应 -
OK Time taken: 5.905 seconds
加载数据语句
一般来说,在SQL中创建表后,我们可以使用Insert语句插入数据。但在 HCatalog 中,我们使用 LOAD DATA 语句插入数据。
在向HCatalog插入数据时,最好使用LOAD DATA来存储批量记录。加载数据有两种方式:一是从本地文件系统加载,二是从Hadoop文件系统加载。
句法
加载数据的语法如下 -
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL 是指定本地路径的标识符。它是可选的。
- OVERWRITE 是可选的,用于覆盖表中的数据。
- 分区是可选的。
例子
我们将向表中插入以下数据。它是/home/user目录中名为sample.txt 的文本文件。
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
以下查询将给定文本加载到表中。
./hcat –e "LOAD DATA LOCAL INPATH '/home/user/sample.txt' OVERWRITE INTO TABLE employee;"
下载成功后,您会看到以下响应 -
OK Time taken: 15.905 seconds
HCatalog - 更改表
本章介绍如何更改表的属性,例如更改表名称、更改列名称、添加列以及删除或替换列。
修改表语句
您可以使用 ALTER TABLE 语句更改 Hive 中的表。
句法
该语句根据我们希望在表中修改的属性采用以下任何语法。
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
下面解释了一些场景。
重命名为...声明
以下查询将表从employee重命名为emp。
./hcat –e "ALTER TABLE employee RENAME TO emp;"
变更声明
下表包含员工表的字段,并显示了要更改的字段(以粗体显示)。
| 字段名称 | 从数据类型转换 | 更改字段名称 | 转换为数据类型 |
|---|---|---|---|
| 开斋节 | 整数 | 开斋节 | 整数 |
| 姓名 | 细绳 | 埃纳姆 | 细绳 |
| 薪水 | 漂浮 | 薪水 | 双倍的 |
| 指定 | 细绳 | 指定 | 细绳 |
以下查询使用上述数据重命名列名称和列数据类型 -
./hcat –e "ALTER TABLE employee CHANGE name ename String;" ./hcat –e "ALTER TABLE employee CHANGE salary salary Double;"
添加列语句
以下查询将名为dept 的列添加到employee表中。
./hcat –e "ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');"
替换语句
以下查询从员工表中删除所有列,并将其替换为emp和name列 -
./hcat – e "ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);"
删除表语句
本章介绍如何删除 HCatalog 中的表。当您从元存储中删除表时,它会删除表/列数据及其元数据。可以是普通表(存储在metastore中)或外部表(存储在本地文件系统中);HCatalog 以相同的方式处理两者,无论其类型如何。
语法如下 -
DROP TABLE [IF EXISTS] table_name;
以下查询删除名为employee的表-
./hcat –e "DROP TABLE IF EXISTS employee;"
成功执行查询后,您将看到以下响应 -
OK Time taken: 5.3 seconds
HC 目录 - 查看
本章介绍如何在 HCatalog 中创建和管理视图。数据库视图是使用CREATE VIEW语句创建的。可以从单个表、多个表或另一个视图创建视图。
要创建视图,根据具体实现,用户必须具有适当的系统权限。
创建视图语句
CREATE VIEW创建具有给定名称的视图。如果同名的表或视图已存在,则会引发错误。您可以使用IF NOT EXISTS来跳过该错误。
如果未提供列名,视图列的名称将从定义的 SELECT 表达式中自动派生。
注意- 如果 SELECT 包含无别名标量表达式(例如 x+y),则结果视图列名称将以 _C0、_C1 等形式生成。
重命名列时,还可以提供列注释。注释不会自动从基础列继承。
如果视图的定义 SELECT 表达式无效,则 CREATE VIEW 语句将失败。
句法
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ...;
例子
以下是员工表数据。现在让我们看看如何创建一个名为Emp_Deg_View的视图,其中包含薪水大于 35,000 的员工的 id、name、Designation 和 salal 字段。
+------+-------------+--------+-------------------+-------+ | ID | Name | Salary | Designation | Dept | +------+-------------+--------+-------------------+-------+ | 1201 | Gopal | 45000 | Technical manager | TP | | 1202 | Manisha | 45000 | Proofreader | PR | | 1203 | Masthanvali | 30000 | Technical writer | TP | | 1204 | Kiran | 40000 | Hr Admin | HR | | 1205 | Kranthi | 30000 | Op Admin | Admin | +------+-------------+--------+-------------------+-------+
以下是根据上述给定数据创建视图的命令。
./hcat –e "CREATE VIEW Emp_Deg_View (salary COMMENT ' salary more than 35,000') AS SELECT id, name, salary, designation FROM employee WHERE salary ≥ 35000;"
输出
OK Time taken: 5.3 seconds
删除视图声明
DROP VIEW 删除指定视图的元数据。当删除其他视图引用的视图时,不会发出警告(从属视图因无效而悬空,必须由用户删除或重新创建)。
句法
DROP VIEW [IF EXISTS] view_name;
例子
以下命令用于删除名为Emp_Deg_View的视图。
DROP VIEW Emp_Deg_View;
HCatalog - 显示表格
您经常想要列出数据库中的所有表或列出表中的所有列。显然,每个数据库都有自己的语法来列出表和列。
Show Tables语句显示所有表的名称。默认情况下,它列出当前数据库中的表,或使用IN子句列出指定数据库中的表。
本章介绍如何在 HCatalog 中列出当前数据库中的所有表。
显示表格声明
SHOW TABLES 的语法如下 -
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
以下查询显示表列表 -
./hcat –e "Show tables;"
成功执行查询后,您将看到以下响应 -
OK emp employee Time taken: 5.3 seconds
HCatalog - 显示分区
分区是表格数据的一个条件,用于创建单独的表或视图。SHOW PARTITIONS 列出给定基表的所有现有分区。分区按字母顺序列出。在 Hive 0.6 之后,还可以指定分区规范的一部分来过滤结果列表。
您可以使用 SHOW PARTITIONS 命令查看特定表中存在的分区。本章介绍如何列出 HCatalog 中特定表的分区。
显示分区声明
语法如下 -
SHOW PARTITIONS table_name;
以下查询删除名为employee的表-
./hcat –e "Show partitions employee;"
成功执行查询后,您将看到以下响应 -
OK Designation = IT Time taken: 5.3 seconds
动态分区
HCatalog 将表组织成分区。它是一种根据日期、城市和部门等分区列的值将表划分为相关部分的方法。使用分区,可以很容易地查询一部分数据。
例如,名为Tab1的表包含员工数据,例如 id、name、dept 和 yoj(即加入年份)。假设您需要检索 2012 年加入的所有员工的详细信息。查询将在整个表中搜索所需的信息。但是,如果将员工数据按年份分区并将其存储在单独的文件中,则会减少查询处理时间。以下示例显示如何对文件及其数据进行分区 -
以下文件包含员工数据表。
/tab1/员工数据/file1
id, name, dept, yoj 1, gopal, TP, 2012 2, kiran, HR, 2012 3, kaleel, SC, 2013 4, Prasanth, SC, 2013
上述数据使用年份划分为两个文件。
/tab1/employeedata/2012/file2
1, gopal, TP, 2012 2, kiran, HR, 2012
/tab1/employeedata/2013/file3
3, kaleel, SC, 2013 4, Prasanth, SC, 2013
添加分区
我们可以通过更改表来向表添加分区。假设我们有一个名为“ employee”的表,其中包含 ID、姓名、薪水、职称、部门和 yoj 等字段。
句法
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
以下查询用于向员工表添加分区。
./hcat –e "ALTER TABLE employee ADD PARTITION (year = '2013') location '/2012/part2012';"
重命名分区
您可以使用 RENAME-TO 命令重命名分区。其语法如下 -
./hact –e "ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;"
以下查询用于重命名分区 -
./hcat –e "ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj='1203');"
删除分区
用于删除分区的命令的语法如下 -
./hcat –e "ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,. PARTITION partition_spec,...;"
以下查询用于删除分区 -
./hcat –e "ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);"
HCatalog - 索引
创建索引
索引只不过是表中特定列上的指针。创建索引意味着在表的特定列上创建指针。其语法如下 -
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name = property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)][ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
例子
让我们举个例子来理解索引的概念。使用我们之前使用的相同员工表,其中包含字段 Id、Name、Salary、Designation 和 Dept。在员工表的工资列上创建一个名为index_salary的索引。
以下查询创建一个索引 -
./hcat –e "CREATE INDEX inedx_salary ON TABLE employee(salary) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';"
它是指向工资列的指针。如果列被修改,则使用索引值存储更改。
删除索引
以下语法用于删除索引 -
DROP INDEX <index_name> ON <table_name>
以下查询删除索引index_salary -
./hcat –e "DROP INDEX index_salary ON employee;"
HCatalog - 读者作家
HCatalog 包含用于并行输入和输出的数据传输 API,无需使用 MapReduce。该 API 使用表和行的基本存储抽象来从 Hadoop 集群读取数据并将数据写入其中。
数据传输API主要包含三个类;这些是 -
HCatReader - 从 Hadoop 集群读取数据。
HCatWriter - 将数据写入 Hadoop 集群。
DataTransferFactory - 生成读取器和写入器实例。
该API适用于主从节点设置。让我们更多地讨论HCatReader和HCatWriter。
HC猫阅读器
HCatReader 是 HCatalog 内部的抽象类,它抽象了要检索记录的底层系统的复杂性。
| S. 编号 | 方法名称和描述 |
|---|---|
| 1 | 公共抽象 ReaderContextprepareRead() 抛出 HCatException 这应该在主节点调用以获得 ReaderContext,然后应该将其序列化并发送到从节点。 |
| 2 | 公共抽象迭代器 <HCatRecorder> read() 抛出 HCaException 这应该在从属节点上调用以读取 HCatRecords。 |
| 3 | 公共配置 getConf() 它将返回配置类对象。 |
HCatReader 类用于从 HDFS 读取数据。读取是一个两步过程,其中第一步发生在外部系统的主节点上。第二步在多个从节点上并行进行。
读取是在ReadEntity上完成的。在开始读取之前,您需要定义一个用于读取的 ReadEntity。这可以通过ReadEntity.Builder来完成。您可以指定数据库名称、表名称、分区和过滤字符串。例如 -
ReadEntity.Builder builder = new ReadEntity.Builder();
ReadEntity entity = builder.withDatabase("mydb").withTable("mytbl").build(); 10.
上面的代码片段定义了一个 ReadEntity 对象(“实体”),包含名为mydb的数据库中名为mytbl的表,可用于读取该表的所有行。请注意,在开始此操作之前,该表必须存在于 HCatalog 中。
定义 ReadEntity 后,您可以使用 ReadEntity 和集群配置获取 HCatReader 的实例 -
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
下一步是从 reader 获取 ReaderContext,如下所示 -
ReaderContext cntxt = reader.prepareRead();
HC猫作家
此抽象是 HCatalog 的内部抽象。这是为了方便从外部系统写入 HCatalog。不要尝试直接实例化它。相反,请使用 DataTransferFactory。
| 先生。 | 方法名称和描述 |
|---|---|
| 1 | 公共抽象 WriterContextprepareRead() 抛出 HCatException 外部系统应该从主节点调用此方法一次。它返回一个WriterContext。这应该被序列化并发送到从节点以在那里构造HCatWriter。 |
| 2 | Public Abstract void write(Iterator<HCatRecord> recordItr) 抛出 HCaException 该方法应该在从节点上使用来执行写入。recordItr 是一个迭代器对象,其中包含要写入 HCatalog 的记录集合。 |
| 3 | 公共抽象 void abort(WriterContext cntxt) 抛出 HCatException 该方法应该在主节点上调用。此方法的主要目的是在发生故障时进行清理。 |
| 4 | 公共抽象无效提交(WriterContext cntxt)抛出HCatException 该方法应该在主节点上调用。该方法的目的是进行元数据提交。 |
与读取类似,写入也是一个两步过程,其中第一步发生在主节点上。随后,第二步在从节点上并行发生。
写入是在WriteEntity上完成的,它可以以类似于读取的方式构建 -
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withDatabase("mydb").withTable("mytbl").build();
上面的代码创建了一个 WriteEntity 对象entity,可用于写入数据库mydb中名为mytbl的表。
创建 WriteEntity 后,下一步是获取 WriterContext -
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config); WriterContext info = writer.prepareWrite();
上述所有步骤都发生在主节点上。然后,主节点序列化 WriterContext 对象并使其可供所有从节点使用。
在从节点上,您需要使用 WriterContext 获取 HCatWriter,如下所示 -
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
然后,作者将迭代器作为该方法的参数write-
writer.write(hCatRecordItr);
然后,编写器在循环中对该迭代器调用getNext()并写出附加到迭代器的所有记录。
TestReaderWriter.java文件用于测试 HCatreader 和 HCatWriter 类。以下程序演示如何使用 HCatReader 和 HCatWriter API 从源文件读取数据,然后将其写入目标文件。
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.ql.CommandNeedRetryException;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hive.HCatalog.common.HCatException;
import org.apache.hive.HCatalog.data.transfer.DataTransferFactory;
import org.apache.hive.HCatalog.data.transfer.HCatReader;
import org.apache.hive.HCatalog.data.transfer.HCatWriter;
import org.apache.hive.HCatalog.data.transfer.ReadEntity;
import org.apache.hive.HCatalog.data.transfer.ReaderContext;
import org.apache.hive.HCatalog.data.transfer.WriteEntity;
import org.apache.hive.HCatalog.data.transfer.WriterContext;
import org.apache.hive.HCatalog.mapreduce.HCatBaseTest;
import org.junit.Assert;
import org.junit.Test;
public class TestReaderWriter extends HCatBaseTest {
@Test
public void test() throws MetaException, CommandNeedRetryException,
IOException, ClassNotFoundException {
driver.run("drop table mytbl");
driver.run("create table mytbl (a string, b int)");
Iterator<Entry<String, String>> itr = hiveConf.iterator();
Map<String, String> map = new HashMap<String, String>();
while (itr.hasNext()) {
Entry<String, String> kv = itr.next();
map.put(kv.getKey(), kv.getValue());
}
WriterContext cntxt = runsInMaster(map);
File writeCntxtFile = File.createTempFile("hcat-write", "temp");
writeCntxtFile.deleteOnExit();
// Serialize context.
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(writeCntxtFile));
oos.writeObject(cntxt);
oos.flush();
oos.close();
// Now, deserialize it.
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(writeCntxtFile));
cntxt = (WriterContext) ois.readObject();
ois.close();
runsInSlave(cntxt);
commit(map, true, cntxt);
ReaderContext readCntxt = runsInMaster(map, false);
File readCntxtFile = File.createTempFile("hcat-read", "temp");
readCntxtFile.deleteOnExit();
oos = new ObjectOutputStream(new FileOutputStream(readCntxtFile));
oos.writeObject(readCntxt);
oos.flush();
oos.close();
ois = new ObjectInputStream(new FileInputStream(readCntxtFile));
readCntxt = (ReaderContext) ois.readObject();
ois.close();
for (int i = 0; i < readCntxt.numSplits(); i++) {
runsInSlave(readCntxt, i);
}
}
private WriterContext runsInMaster(Map<String, String> config) throws HCatException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();
return info;
}
private ReaderContext runsInMaster(Map<String, String> config,
boolean bogus) throws HCatException {
ReadEntity entity = new ReadEntity.Builder().withTable("mytbl").build();
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
ReaderContext cntxt = reader.prepareRead();
return cntxt;
}
private void runsInSlave(ReaderContext cntxt, int slaveNum) throws HCatException {
HCatReader reader = DataTransferFactory.getHCatReader(cntxt, slaveNum);
Iterator<HCatRecord> itr = reader.read();
int i = 1;
while (itr.hasNext()) {
HCatRecord read = itr.next();
HCatRecord written = getRecord(i++);
// Argh, HCatRecord doesnt implement equals()
Assert.assertTrue("Read: " + read.get(0) + "Written: " + written.get(0),
written.get(0).equals(read.get(0)));
Assert.assertTrue("Read: " + read.get(1) + "Written: " + written.get(1),
written.get(1).equals(read.get(1)));
Assert.assertEquals(2, read.size());
}
//Assert.assertFalse(itr.hasNext());
}
private void runsInSlave(WriterContext context) throws HCatException {
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
writer.write(new HCatRecordItr());
}
private void commit(Map<String, String> config, boolean status,
WriterContext context) throws IOException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
if (status) {
writer.commit(context);
} else {
writer.abort(context);
}
}
private static HCatRecord getRecord(int i) {
List<Object> list = new ArrayList<Object>(2);
list.add("Row #: " + i);
list.add(i);
return new DefaultHCatRecord(list);
}
private static class HCatRecordItr implements Iterator<HCatRecord> {
int i = 0;
@Override
public boolean hasNext() {
return i++ < 100 ? true : false;
}
@Override
public HCatRecord next() {
return getRecord(i);
}
@Override
public void remove() {
throw new RuntimeException();
}
}
}
上面的程序从HDFS中以记录的形式读取数据,并将记录数据写入到mytable中
HCatalog - 输入输出格式
HCatInputFormat和HCatOutputFormat接口用于从 HDFS 读取数据,并在处理后使用 MapReduce 作业将结果数据写入 HDFS 。让我们详细说明输入和输出格式接口。
HCat输入格式
HCatInputFormat与 MapReduce 作业一起使用,从 HCatalog 管理的表中读取数据。HCatInputFormat 公开了 Hadoop 0.20 MapReduce API,用于读取数据,就像数据已发布到表中一样。
| 先生。 | 方法名称和描述 |
|---|---|
| 1 | 公共静态 HCatInputFormat setInput(Job job, String dbName, String tableName) 抛出 IOException 设置用于作业的输入。它使用给定的输入规范查询元存储,并将匹配的分区序列化到 MapReduce 任务的作业配置中。 |
| 2 | 公共静态 HCatInputFormat setInput(配置conf,字符串dbName,字符串表名)抛出IOException 设置用于作业的输入。它使用给定的输入规范查询元存储,并将匹配的分区序列化到 MapReduce 任务的作业配置中。 |
| 3 | public HCatInputFormat setFilter(字符串过滤器)抛出 IOException 在输入表上设置过滤器。 |
| 4 | 公共 HCatInputFormat setProperties(Properties 属性) 抛出 IOException 设置输入格式的属性。 |
HCatInputFormat API 包括以下方法 -
- 设置输入
- 设置输出模式
- 获取表模式
要使用HCatInputFormat读取数据,首先使用正在读取的表中的必要信息实例化一个InputJobInfo ,然后使用该InputJobInfo调用setInput。
您可以使用setOutputSchema方法包含投影模式,以指定输出字段。如果未指定架构,则将返回表中的所有列。您可以使用 getTableSchema 方法来确定指定输入表的表架构。
HCat输出格式
HCatOutputFormat 与 MapReduce 作业一起使用,将数据写入 HCatalog 管理的表。HCatOutputFormat 公开了 Hadoop 0.20 MapReduce API,用于将数据写入表。当 MapReduce 作业使用 HCatOutputFormat 写入输出时,将使用为表配置的默认 OutputFormat,并在作业完成后将新分区发布到表。
| 先生。 | 方法名称和描述 |
|---|---|
| 1 | 公共静态无效setOutput(配置conf,凭据凭据,OutputJobInfo输出JobInfo)抛出IOException 设置有关要为作业写入的输出的信息。它查询元数据服务器以查找用于表的 StorageHandler。如果分区已发布,则会抛出错误。 |
| 2 | public static void setSchema(配置conf,HCatSchema架构)抛出IOException 设置写入分区的数据的架构。如果未调用,则默认情况下将表架构用于分区。 |
| 3 | public RecordWriter <WritableComparable<?>, HCatRecord > getRecordWriter (TaskAttemptContext context) 抛出 IOException、InterruptedException 找一位唱片作家来做这份工作。它使用 StorageHandler 的默认 OutputFormat 来获取记录写入器。 |
| 4 | public OutputCommitter getOutputCommitter (TaskAttemptContext context) 抛出 IOException、InterruptedException 获取此输出格式的输出提交者。它确保正确提交输出。 |
HCatOutputFormat API包括以下方法 -
- 设置输出
- 设置模式
- 获取表模式
对 HCatOutputFormat 的第一次调用必须是setOutput;任何其他调用都会抛出异常,表示输出格式未初始化。
写出的数据的架构由setSchema方法指定。您必须调用此方法,并提供您正在编写的数据的架构。如果您的数据与表架构具有相同的架构,则可以使用HCatOutputFormat.getTableSchema()获取表架构,然后将其传递给setSchema()。
例子
以下 MapReduce 程序从一个表中读取数据,假设该表的第二列(“第 1 列”)中有一个整数,并计算它找到的每个不同值的实例数。也就是说,它相当于“ select col1, count(*) from $table group by col1; ”。
例如,如果第二列中的值为 {1, 1, 1, 3, 3, 5},则程序将产生以下值和计数输出 -
1, 3 3, 2 5, 1
现在让我们看一下程序代码 -
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.HCatalog.common.HCatConstants;
import org.apache.HCatalog.data.DefaultHCatRecord;
import org.apache.HCatalog.data.HCatRecord;
import org.apache.HCatalog.data.schema.HCatSchema;
import org.apache.HCatalog.mapreduce.HCatInputFormat;
import org.apache.HCatalog.mapreduce.HCatOutputFormat;
import org.apache.HCatalog.mapreduce.InputJobInfo;
import org.apache.HCatalog.mapreduce.OutputJobInfo;
public class GroupByAge extends Configured implements Tool {
public static class Map extends Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable> {
int age;
@Override
protected void map(
WritableComparable key, HCatRecord value,
org.apache.hadoop.mapreduce.Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable>.Context context
)throws IOException, InterruptedException {
age = (Integer) value.get(1);
context.write(new IntWritable(age), new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord> {
@Override
protected void reduce(
IntWritable key, java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord>.Context context
)throws IOException ,InterruptedException {
int sum = 0;
Iterator<IntWritable> iter = values.iterator();
while (iter.hasNext()) {
sum++;
iter.next();
}
HCatRecord record = new DefaultHCatRecord(2);
record.set(0, key.get());
record.set(1, sum);
context.write(null, record);
}
}
public int run(