自动机理论 - 快速指南
自动机理论简介
自动机——它是什么?
“自动机”一词源自希腊语“αὐτόματα”,意思是“自作用”。自动机(复数Automata)是一种抽象的自驱动计算设备,它自动遵循预定的操作顺序。
具有有限状态数的自动机称为有限自动机(FA)或有限状态机(FSM)。
有限自动机的正式定义
自动机可以用 5 元组 (Q, Σ, δ, q 0 , F)表示,其中 -
Q是有限状态集。
Σ是有限符号集,称为自动机字母表。
δ是过渡函数。
q 0是处理任何输入的初始状态 (q 0 ∈ Q)。
F是 Q 的最终状态的集合 (F ⊆ Q)。
相关术语
字母
定义-字母表是任何有限的符号集。
示例- Σ = {a, b, c, d} 是一个字母集,其中 'a'、'b'、'c' 和 'd' 是符号。
细绳
定义-字符串是取自 Σ 的有限符号序列。
示例- 'cabcad' 是字母集 Σ = {a, b, c, d} 上的有效字符串
字符串的长度
定义- 它是字符串中存在的符号数量。(用|S|表示)。
例子-
如果 S = 'cabcad',|S|= 6
如果 |S|= 0,则称为空串(用λ或ε表示)
克林星
定义- Kleene 星Σ*是一组符号或字符串Σ上的一元运算符,它给出了 Σ 上所有可能长度的所有可能字符串的无限集合,包括λ。
表示− Σ* = Σ 0 ∪ Σ 1 ∪ Σ 2 ∪……。其中 Σ p是长度为 p 的所有可能字符串的集合。
示例- 如果 Σ = {a, b}, Σ* = {λ, a, b, aa, ab, ba, bb,………..}
Kleene 闭合 / Plus
定义- 集合Σ +是 Σ 上所有可能长度的所有可能字符串的无限集合(不包括 λ)。
表示− Σ + = Σ 1 ∪ Σ 2 ∪ Σ 3 ∪……。
Σ + = Σ* − { λ }
示例- 如果 Σ = { a, b } , Σ + = { a, b, aa, ab, ba, bb,………..}
语言
定义- 语言是某些字母表 Σ 的 Σ* 的子集。它可以是有限的或无限的。
示例- 如果语言在 Σ = {a, b} 上采用长度为 2 的所有可能字符串,则 L = { ab, aa, ba, bb }
确定性有限自动机
有限自动机可以分为两种类型 -
- 确定性有限自动机 (DFA)
- 非确定性有限自动机 (NDFA / NFA)
确定性有限自动机 (DFA)
在 DFA 中,对于每个输入符号,我们可以确定机器将移动到的状态。因此,它被称为确定性自动机。由于它具有有限数量的状态,因此该机器被称为确定性有限机或确定性有限自动机。
DFA 的正式定义
DFA 可以用 5 元组 (Q, Σ, δ, q 0 , F) 表示,其中 -
Q是有限状态集。
Σ是称为字母表的有限符号集。
δ是过渡函数,其中 δ: Q × Σ → Q
q 0是处理任何输入的初始状态 (q 0 ∈ Q)。
F是 Q 的最终状态的集合 (F ⊆ Q)。
DFA 的图形表示
DFA 由称为状态图的有向图表示。
- 顶点代表状态。
- 标有输入字母的弧线显示了转换。
- 初始状态由空的单个传入弧表示。
- 最终状态由双圆圈表示。
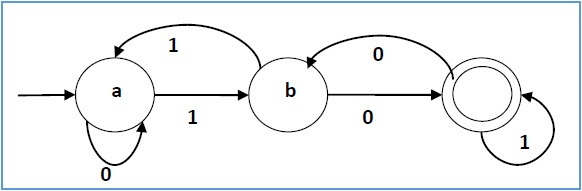
例子
设确定性有限自动机为 →
- Q = {a, b, c},
- Σ = {0, 1},
- q 0 = {a},
- F = {c},并且
转移函数 δ 如下表所示 -
| 现状 | 输入 0 的下一个状态 | 输入 1 的下一个状态 |
|---|---|---|
| A | A | 乙 |
| 乙 | C | A |
| C | 乙 | C |
其图形表示如下 -
非确定性有限自动机
在NDFA中,对于特定的输入符号,机器可以移动到机器中状态的任意组合。换句话说,无法确定机器移动到的确切状态。因此,它被称为非确定性自动机。由于它具有有限数量的状态,该机器被称为非确定性有限机器或非确定性有限自动机。
NDFA 的正式定义
NDFA 可以用 5 元组 (Q, Σ, δ, q 0 , F) 表示,其中 -
Q是有限状态集。
Σ是称为字母表的有限符号集。
δ是过渡函数,其中 δ: Q × Σ → 2 Q
(这里采用了Q (2 Q )的幂集,因为在 NDFA 的情况下,从一个状态可以发生到 Q 状态的任意组合的转换)
q 0是处理任何输入的初始状态 (q 0 ∈ Q)。
F是 Q 的最终状态的集合 (F ⊆ Q)。
NDFA 的图形表示:(与 DFA 相同)
NDFA 由称为状态图的有向图表示。
- 顶点代表状态。
- 标有输入字母的弧线显示了转换。
- 初始状态由空的单个传入弧表示。
- 最终状态由双圆圈表示。
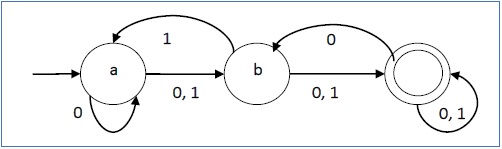
例子
设一个非确定性有限自动机为 →
- Q = {a, b, c}
- Σ = {0, 1}
- q 0 = {a}
- F = {c}
转换函数 δ 如下所示 -
| 现状 | 输入 0 的下一个状态 | 输入 1 的下一个状态 |
|---|---|---|
| A | 甲、乙 | 乙 |
| 乙 | C | 一、三 |
| C | 乙、丙 | C |
其图形表示如下 -
DFA 与 NDFA
下表列出了 DFA 和 NDFA 之间的差异。
| DFA | NDFA |
|---|---|
| 对于每个输入符号,从一个状态到一个特定的下一个状态的转换。因此它被称为确定性的。 | 对于每个输入符号,从一个状态到多个下一个状态的转换可以是。因此它被称为非确定性的。 |
| 在 DFA 中看不到空字符串转换。 | NDFA 允许空字符串转换。 |
| DFA 中允许回溯 | 在 NDFA 中,回溯并不总是可能的。 |
| 需要更多空间。 | 需要更少的空间。 |
| 如果字符串转变为最终状态,则 DFA 接受该字符串。 | 如果所有可能的转换中至少有一个以最终状态结束,则 NDFA 接受字符串。 |
接受器、分类器和转换器
接受器(识别器)
计算布尔函数的自动机称为接受器。接受器的所有状态要么接受,要么拒绝给它的输入。
分类器
分类器有两个以上的最终状态,并且在终止时给出单个输出。
传感器
根据当前输入和/或先前状态产生输出的自动机称为传感器。传感器可以有两种类型 -
Mealy Machine - 输出取决于当前状态和当前输入。
摩尔机- 输出仅取决于当前状态。
DFA 和 NDFA 的可接受性
如果从初始状态开始的 DFA/NDFA 在完全读取字符串后以接受状态(任何最终状态)结束,则字符串被 DFA/NDFA 接受。
字符串 S 被 DFA/NDFA 接受 (Q, Σ, δ, q 0 , F), iff
δ*(q 0 , S) ∈ F
DFA/NDFA接受的语言L是
{S | S ε Σ* 且 δ*(q 0 , S) ε F}
DFA/NDFA 不接受字符串 S′ (Q, Σ, δ, q 0 , F), iff
δ*(q 0 , S′) ∉ F
DFA/NDFA 不接受的语言 L′(接受语言 L 的补集)是
{S | S ∈ Σ* 且 δ*(q 0 , S) ∉ F}
例子
让我们考虑一下图 1.3 中所示的 DFA。从 DFA 中,可以导出可接受的字符串。
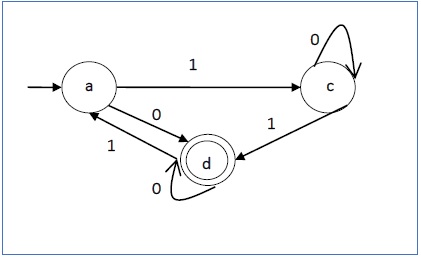
上述 DFA 接受的字符串:{0, 00, 11, 010, 101, ...........}
上述 DFA 不接受的字符串:{1, 011, 111, ........}
NDFA 到 DFA 转换
问题陈述
令X = (Q x , Σ, δ x , q 0 , F x )为接受语言 L(X) 的 NDFA。我们必须设计一个等效的 DFA Y = (Q y , Σ, δ y , q 0 , F y )使得L(Y) = L(X)。以下过程将 NDFA 转换为其等效的 DFA -
算法
输入- NDFA
输出- 等效的 DFA
步骤 1 - 根据给定的 NDFA 创建状态表。
步骤 2 - 在等效 DFA 的可能输入字母下创建一个空白状态表。
步骤 3 - 用 q0 标记 DFA 的开始状态(与 NDFA 相同)。
步骤 4 - 找出每个可能的输入字母表的状态 {Q 0 , Q 1 ,... , Q n } 的组合。
步骤 5 - 每次我们在输入字母列下生成新的 DFA 状态时,我们都必须再次应用步骤 4,否则转到步骤 6。
步骤 6 - 包含 NDFA 任何最终状态的状态是等效 DFA 的最终状态。
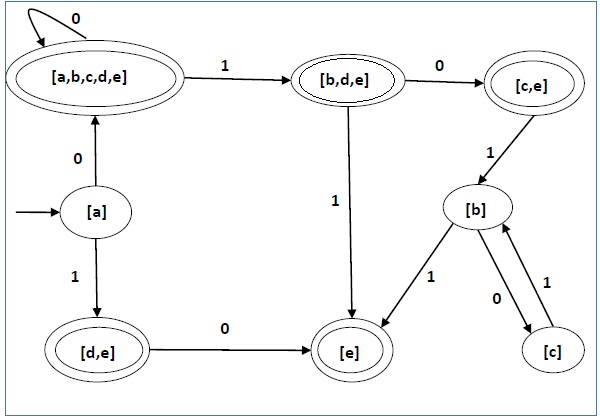
例子
让我们考虑下图所示的 NDFA。
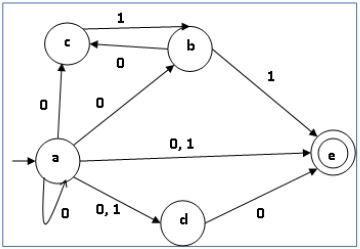
| q | δ(q,0) | δ(q,1) |
|---|---|---|
| A | {a,b,c,d,e} | {d,e} |
| 乙 | {C} | {e} |
| C | ∅ | {b} |
| d | {e} | ∅ |
| e | ∅ | ∅ |
使用上述算法,我们找到其等价的DFA。DFA的状态表如下所示。
| q | δ(q,0) | δ(q,1) |
|---|---|---|
| [A] | [a、b、c、d、e] | [d,e] |
| [a、b、c、d、e] | [a、b、c、d、e] | [b、d、e] |
| [d,e] | [e] | ∅ |
| [b、d、e] | [c,e] | [e] |
| [e] | ∅ | ∅ |
| [c、e] | ∅ | [b] |
| [b] | [C] | [e] |
| [C] | ∅ | [b] |
DFA 的状态图如下 -
DFA 最小化
使用 Myhill-Nerode 定理的 DFA 最小化
算法
输入- DFA
输出- 最小化 DFA
步骤 1 - 为不一定直接连接的所有状态对 (Q i , Q j ) 绘制一个表格 [所有状态最初都未标记]
步骤 2 - 考虑DFA 中的每个状态对 (Q i , Q j ),其中 Q i ∈ F 且 Q j ∉ F 或反之亦然,并标记它们。[这里F是最终状态的集合]
步骤 3 - 重复此步骤,直到我们无法再标记状态 -
如果存在未标记的对 (Q i , Q j ),如果对某个输入字母表标记了对{δ (Q i , A), δ (Q i , A)} ,则对其进行标记。
步骤 4 - 组合所有未标记的对 (Q i , Q j ) 并使它们成为简化 DFA 中的单个状态。
例子
让我们使用算法 2 来最小化如下所示的 DFA。

步骤 1 - 我们为所有状态对绘制一个表格。
| A | 乙 | C | d | e | F | |
| A | ||||||
| 乙 | ||||||
| C | ||||||
| d | ||||||
| e | ||||||
| F |
步骤 2 - 我们标记状态对。
| A | 乙 | C | d | e | F | |
| A | ||||||
| 乙 | ||||||
| C | ✔ | ✔ | ||||
| d | ✔ | ✔ | ||||
| e | ✔ | ✔ | ||||
| F | ✔ | ✔ | ✔ |
步骤 3 - 我们将尝试用绿色复选标记传递地标记状态对。如果我们在状态‘a’和‘f’输入1,它将分别进入状态‘c’和‘f’。(c, f) 已经被标记,因此我们将标记对 (a, f)。现在,我们在状态'b'和'f'中输入1;它将分别进入状态“d”和“f”。(d, f) 已经被标记,因此我们将标记对 (b, f)。
| A | 乙 | C | d | e | F | |
| A | ||||||
| 乙 | ||||||
| C | ✔ | ✔ | ||||
| d | ✔ | ✔ | ||||
| e | ✔ | ✔ | ||||
| F | ✔ | ✔ | ✔ | ✔ | ✔ |
经过步骤 3,我们得到了未标记的状态组合 {a, b} {c, d} {c, e} {d, e}。
我们可以将 {c, d} {c, e} {d, e} 重新组合为 {c, d, e}
因此我们得到两个组合状态 - {a, b} 和 {c, d, e}
因此最终的最小化 DFA 将包含三个状态 {f}、{a, b} 和 {c, d, e}
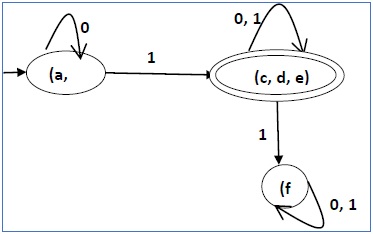
使用等价定理的 DFA 最小化
如果X和Y是DFA中的两个状态,如果这两个状态不可区分,我们可以将这两个状态组合成{X,Y}。如果至少有一个字符串 S,使得 δ (X, S) 和 δ (Y, S) 之一接受而另一个不接受,则两种状态是可区分的。因此,当且仅当所有状态都是可区分的时,DFA 才是最小的。
算法3
步骤 1 - 所有状态Q分为两个部分 -最终状态和非最终状态,并用P 0表示。分区中的所有状态都是第 0等价的。取一个计数器k并将其初始化为 0。
步骤 2 - 将 k 加 1。对于 P k中的每个分区,如果 P k中的状态是 k 可区分的,则将它们分为两个分区。如果存在输入S使得δ(X, S)和δ(Y, S)是 (k-1) 可区分的,则此分区 X 和 Y 内的两个状态是 k 可区分的。
步骤 3 - 如果 P k ≠ P k-1,则重复步骤 2,否则转至步骤 4。
步骤 4 - 组合第 k个等效集并使它们成为简化 DFA 的新状态。
例子
让我们考虑以下 DFA -
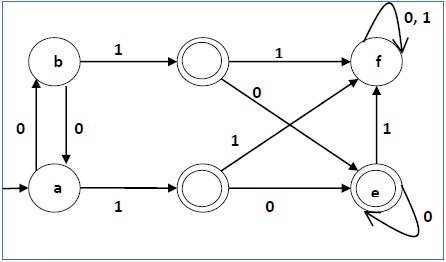
| q | δ(q,0) | δ(q,1) |
|---|---|---|
| A | 乙 | C |
| 乙 | A | d |
| C | e | F |
| d | e | F |
| e | e | F |
| F | F | F |
让我们将上述算法应用于上述 DFA -
- P 0 = {(c,d,e), (a,b,f)}
- P 1 = {(c,d,e), (a,b),(f)}
- P 2 = {(c,d,e), (a,b),(f)}
因此,P 1 = P 2。
简化的 DFA 中有 3 个状态。减少的 DFA 如下 -
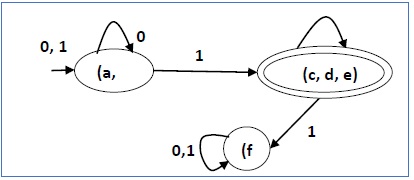
| 问 | δ(q,0) | δ(q,1) |
|---|---|---|
| (一、二) | (一、二) | (c、d、e) |
| (c、d、e) | (c、d、e) | (F) |
| (F) | (F) | (F) |
摩尔和米利机器
有限自动机可以具有与每个转换相对应的输出。有两种类型的有限状态机生成输出 -
- 打粉机
- 摩尔机
打粉机
Mealy Machine 是一种 FSM,其输出取决于当前状态以及当前输入。
它可以用 6 元组 (Q, Σ, O, δ, X, q 0 )来描述,其中 -
Q是有限状态集。
Σ是一组有限的符号,称为输入字母表。
O是一组有限的符号,称为输出字母表。
δ是输入转换函数,其中 δ: Q × Σ → Q
X是输出转换函数,其中 X: Q × Σ → O
q 0是处理任何输入的初始状态 (q 0 ∈ Q)。
Mealy Machine 的状态表如下所示 -
| 目前状态 | 下一个状态 | |||
|---|---|---|---|---|
| 输入 = 0 | 输入 = 1 | |||
| 状态 | 输出 | 状态 | 输出 | |
| → 一个 | 乙 | x 1 | C | x 1 |
| 乙 | 乙 | x 2 | d | x 3 |
| C | d | x 3 | C | x 1 |
| d | d | x 3 | d | x 2 |
上述 Mealy 机的状态图是 -
摩尔机
摩尔机是一个 FSM,其输出仅取决于当前状态。
摩尔机可以用 6 元组 (Q, Σ, O, δ, X, q 0 ) 来描述,其中 -
Q是有限状态集。
Σ是一组有限的符号,称为输入字母表。
O是一组有限的符号,称为输出字母表。
δ是输入转换函数,其中 δ: Q × Σ → Q
X是输出转换函数,其中 X: Q → O
q 0是处理任何输入的初始状态 (q 0 ∈ Q)。
摩尔机的状态表如下所示 -
| 目前状态 | 下一个状态 | 输出 | |
|---|---|---|---|
| 输入 = 0 | 输入 = 1 | ||
| → 一个 | 乙 | C | x 2 |
| 乙 | 乙 | d | x 1 |
| C | C | d | x 2 |
| d | d | d | x 3 |
上述摩尔机的状态图是 -
Mealy 机与 Moore 机
下表重点介绍了 Mealy 机器与 Moore 机器的区别点。
| 打粉机 | 摩尔机 |
|---|---|
| 输出取决于当前状态和当前输入 | 输出仅取决于当前状态。 |
| 一般来说,它的状态比摩尔机少。 | 一般来说,它比Mealy Machine有更多的状态。 |
| 当当前状态的输入逻辑完成时,输出函数的值是转换和变化的函数。 | 每当状态发生变化时,输出函数的值是当前状态和时钟边沿变化的函数。 |
| Mealy 机器对输入的反应更快。它们通常在同一时钟周期内做出反应。 | 在摩尔机器中,需要更多的逻辑来解码输出,从而导致更多的电路延迟。它们通常会在一个时钟周期后做出反应。 |
摩尔机到麦利机
算法4
输入- 摩尔机
输出- Mealy 机
步骤 1 - 采用空白 Mealy Machine 转换表格式。
步骤 2 - 将所有摩尔机过渡状态复制到此表格式中。
步骤 3 - 检查摩尔机状态表中的当前状态及其相应的输出;如果状态 Q i 的输出是 m,则将其复制到 Mealy Machine 状态表的输出列中,无论 Q i出现在下一个状态中。
例子
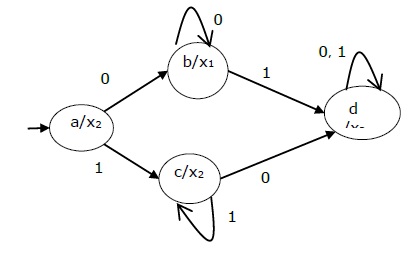
让我们考虑以下摩尔机 -
| 现状 | 下一个状态 | 输出 | |
|---|---|---|---|
| a = 0 | 一个= 1 | ||
| → 一个 | d | 乙 | 1 |
| 乙 | A | d | 0 |
| C | C | C | 0 |
| d | 乙 | A | 1 |
现在我们应用算法 4 将其转换为 Mealy Machine。
步骤 1 和 2 -
| 现状 | 下一个状态 | |||
|---|---|---|---|---|
| a = 0 | 一个= 1 | |||
| 状态 | 输出 | 状态 | 输出 | |
| → 一个 | d | 乙 | ||
| 乙 | A | d | ||
| C | C | C | ||
| d | 乙 | A | ||
步骤 3 -
| 现状 | 下一个状态 | |||
|---|---|---|---|---|
| a = 0 | 一个= 1 | |||
| 状态 | 输出 | 状态 | 输出 | |
| => 一个 | d | 1 | 乙 | 0 |
| 乙 | A | 1 | d | 1 |
| C | C | 0 | C | 0 |
| d | 乙 | 0 | A | 1 |
粉机到摩尔机
算法5
输入- Mealy 机
输出- 摩尔机
步骤 1 - 计算Mealy 机状态表中可用的每个状态 (Q i )的不同输出的数量。
步骤 2 - 如果 Qi 的所有输出都相同,则复制状态 Q i。如果它有 n 个不同的输出,则将 Q i分成 n 个状态,如 Q in其中n = 0, 1, 2.......
步骤 3 - 如果初始状态的输出为 1,则在开头插入一个新的初始状态,该状态给出 0 输出。
例子
让我们考虑以下 Mealy Machine -
| 现状 | 下一个状态 | |||
|---|---|---|---|---|
| a = 0 | 一个= 1 | |||
| 下一个状态 | 输出 | 下一个状态 | 输出 | |
| → 一个 | d | 0 | 乙 | 1 |
| 乙 | A | 1 | d | 0 |
| C | C | 1 | C | 0 |
| d | 乙 | 0 | A | 1 |
这里,状态“a”和“d”分别仅给出 1 和 0 输出,因此我们保留状态“a”和“d”。但状态“b”和“c”产生不同的输出(1 和 0)。因此,我们将b分为b 0、 b 1,将c分为c 0、 c 1。
| 现状 | 下一个状态 | 输出 | |
|---|---|---|---|
| a = 0 | 一个= 1 | ||
| → 一个 | d | 乙1 | 1 |
| 乙0 | A | d | 0 |
| 乙1 | A | d | 1 |
| 0 _ | c 1 | C 0 | 0 |
| c 1 | c 1 | C 0 | 1 |
| d | 乙0 | A | 0 |
语法简介
在该术语的文学意义上,语法表示自然语言中对话的句法规则。自从英语、梵语、普通话等自然语言诞生以来,语言学就一直试图定义语法。
形式语言理论在计算机科学领域有着广泛的应用。诺姆·乔姆斯基 (Noam Chomsky)在 1956 年给出了语法的数学模型,该模型对于编写计算机语言非常有效。
语法
语法G可以正式写为 4 元组 (N, T, S, P),其中 -
N或V N是一组变量或非终结符。
T或Σ是一组终结符号。
S是一个特殊变量,称为起始符号,S ∈ N
P是终结符和非终结符的产生式规则。产生式规则的形式为 α → β,其中 α 和 β 是 V N ∪ Σ上的串,并且 α 的至少一个符号属于 V N。
例子
语法 G1 -
({S, A, B}, {a, b}, S, {S → AB, A → a, B → b})
这里,
S、A、 B为非终结符号;
a和b是终结符
S是起始符号,S ∈ N
产生式,P:S → AB,A → a,B → b
例子
语法 G2 -
(({S, A}, {a, b}, S,{S → aAb, aA → aaAb, A → ε } )
这里,
S和A是非终结符。
a和b是终结符号。
ε是一个空字符串。
S是起始符号,S ∈ N
生产P : S → aAb, aA → aaAb, A → ε
语法的推导
字符串可以使用语法中的产生式从其他字符串派生出来。如果文法G具有产生式α → β,我们可以说x α y导出G中的x β y。这个推导写成 -
x α y ⇒ G x β y
例子
让我们考虑语法 -
G2 = ({S, A}, {a, b}, S, {S → aAb, aA → aaAb, A → ε } )
一些可以导出的字符串是 -
S ⇒ aA b使用产生式 S → aAb
⇒ a aA bb使用产生式 aA → aAb
⇒ aaa A bbb使用产生式 aA → aaAb
⇒ aaabbb使用产生式 A → ε
由语法生成的语言
可以从语法派生的所有字符串的集合被称为从该语法生成的语言。由文法G生成的语言是由下式正式定义的子集
L(G)={W|W ∈ Σ*, S ⇒ G W }
如果L(G1) = L(G2),则语法G1等同于语法G2。
例子
如果有语法的话
G: N = {S, A, B} T = {a, b} P = {S → AB, A → a, B → b}
这里S生成AB,我们可以用a替换A,用b替换B。在这里,唯一接受的字符串是ab,即
L(G) = {ab}
例子
假设我们有以下语法 -
G: N = {S, A, B} T = {a, b} P = {S → AB, A → aA|a, B → bB|b}
该语法生成的语言 -
L(G) = {ab, a 2 b, ab 2 , a 2 b 2 , ………}
= {a m b n | m ≥ 1 且 n ≥ 1}
构建语法生成语言
我们将考虑一些语言并将其转换为生成这些语言的语法 G。
例子
问题- 假设 L (G) = {a m b n | m ≥ 0 且 n > 0}。我们必须找出产生L(G)的语法G。
解决方案
由于 L(G) = {a m b n | m ≥ 0 且 n > 0}
接受的字符串集可以重写为 -
L(G) = {b, ab,bb, aab, abb, …….}
这里,起始符号必须至少有一个“b”,前面有任意数量的“a”,包括空值。
为了接受字符串集 {b, ab, bb, aab, abb, …….},我们采用了产生式 -
S → aS 、S → B、B → b 和 B → bB
S → B → b(已接受)
S → B → bB → bb(已接受)
S → aS → aB → ab(已接受)
S → aS → aaS → aaB → aab(已接受)
S → aS → aB → abB → abb (已接受)
因此,我们可以证明 L(G) 中的每个字符串都被产生集生成的语言所接受。
因此语法 -
G: ({S, A, B}, {a, b}, S, { S → aS | B , B → b | bB })
例子
问题- 假设 L (G) = {a m b n | m > 0 且 n ≥ 0}。我们必须找出产生 L(G) 的文法 G。
解决方案-
由于 L(G) = {a m b n | m > 0 且 n ≥ 0},接受的字符串集合可以重写为 -
L(G) = {a, aa, ab, aaa, aab ,abb, …….}
这里,起始符号必须至少采用一个“a”,后跟任意数量的“b”,包括空值。
为了接受字符串集合 {a, aa, ab, aaa, aab, abb, …….},我们采用了产生式 -
S→aA,A→aA,A→B,B→bB,B→λ
S → aA → aB → aλ → a(已接受)
S → aA → aaA → aaB → aaλ → aa (已接受)
S → aA → aB → abB → abλ → ab (已接受)
S → aA → aaA → aaaA → aaaB → aaaλ → aaa (已接受)
S → aA → aaA → aaB → aabB → aabλ → aab (已接受)
S → aA → aB → abB → abbB → abbλ → abb (已接受)
因此,我们可以证明 L(G) 中的每个字符串都被产生集生成的语言所接受。
因此语法 -
G: ({S, A, B}, {a, b}, S, {S → aA, A → aA | B, B → λ | bB })
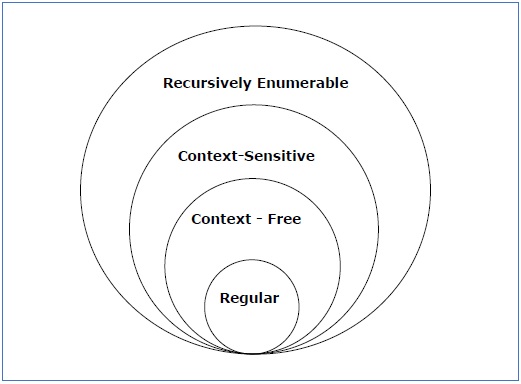
乔姆斯基语法分类
根据诺姆·乔莫斯基 (Noam Chomosky) 的说法,语法有四种类型 - 类型 0、类型 1、类型 2 和类型 3。下表显示了它们之间的区别 -
| 语法类型 | 语法已接受 | 接受语言 | 自动机 |
|---|---|---|---|
| 0型 | 不受语法限制 | 递归可枚举语言 | 图灵机 |
| 类型1 | 上下文相关语法 | 上下文相关语言 | 线性有界自动机 |
| 2型 | 上下文无关语法 | 上下文无关语言 | 下推自动机 |
| 3型 | 正则语法 | 常规语言 | 有限状态自动机 |
看看下面的插图。它显示了每种语法类型的范围 -
类型 - 3 语法
Type-3 语法生成常规语言。类型 3 语法必须在左侧有一个非终结符,右侧必须包含一个终结符或单个终结符后跟一个非终结符。
产品必须采用X → a 或 X → aY 的形式
其中X, Y ∈ N(非终结符)
和a ∈ T(终端)
如果S没有出现在任何规则的右侧,则规则S → ε是允许的。
例子
X → ε X → a | aY Y → b
类型 - 2 语法
Type-2 语法生成上下文无关语言。
产生式必须采用A → γ的形式
其中A ∈ N(非终结符)
和γ ∈ (T ∪ N)*(终结符和非终结符串)。
由这些语法生成的这些语言由非确定性下推自动机识别。
例子
S → X a X → a X → aX X → abc X → ε
类型 - 1 语法
Type-1 语法生成上下文相关语言。作品必须采用以下形式
α A β → α γ β
其中A ∈ N(非终结符)
和α, β, γ ∈ (T ∪ N)*(终结符和非终结符串)
字符串α和β可以为空,但γ必须非空。
如果 S 没有出现在任何规则的右侧,则规则S → ε是允许的。这些语法生成的语言由线性有界自动机识别。
例子
AB → AbBc A → bcA B → b
类型 - 0 语法
Type-0 语法生成递归可枚举语言。制作没有任何限制。它们是任何阶段结构语法,包括所有形式语法。
它们生成图灵机可以识别的语言。
产品可以采用α → β的形式,其中α是一串终结符和非终结符,其中至少有一个非终结符,并且α不能为空。β是一串终结符和非终结符。
例子
S → ACaB Bc → acB CB → DB aD → Db
常用表达
正则表达式可以递归定义如下 -
ε是正则表达式,表示包含空字符串的语言。(L(ε) = {ε})
φ是表示空语言的正则表达式。(L(φ) = { })
x是正则表达式,其中L = {x}
如果X是表示语言L(X)的正则表达式,Y是表示语言L(Y)的正则表达式,则
X + Y是对应于语言L(X) ∪ L(Y) 的正则表达式,其中L(X+Y) = L(X) ∪ L(Y)。
X 。Y是对应于语言 L(X) 的正则表达式。L(Y),其中L(XY) = L(X) 。左(Y)
R*是对应于语言L(R*)的正则表达式,其中L(R*) = (L(R))*
如果我们多次应用任何规则(从 1 到 5),它们就是正则表达式。
一些正则表达式的例子
| 常用表达 | 常规套装 |
|---|---|
| (0 + 10*) | L = { 0, 1, 10, 100, 1000, 10000, … } |
| (0*10*) | L = {1, 01, 10, 010, 0010, …} |
| (0 + ε)(1 + ε) | L = {ε, 0, 1, 01} |
| (a+b)* | 任意长度的 a 和 b 字符串集,包括空字符串。所以 L = { ε, a, b, aa , ab , bb , ba, aaa......} |
| (a+b)*abb | 以字符串 abb 结尾的 a 和 b 字符串的集合。所以 L = {abb, aabb, babb, aaabb, aabb, …………..} |
| (11)* | 由偶数个 1(包括空字符串)组成的集合,因此 L= {ε, 11, 1111, 111111, ……….} |
| (aa)*(bb)*b | 由偶数个 a 和奇数个 b 组成的字符串集合,因此 L = {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, …………..} |
| (aa + ab + ba + bb)* | 将字符串 aa、ab、ba、bb 的任意组合(包括 null)连接起来可以得到偶数长度的 a 和 b 的字符串,因此 L = {aa, ab, ba, bb, aaab, aaba, ………….. } |
常规套装
任何表示正则表达式值的集合称为正则集。
正则集的性质
财产1.两个正则集的并集是正则的。
证明-
让我们看两个正则表达式
RE 1 = a(aa)* 且 RE 2 = (aa)*
因此,L 1 = {a, aaa, aaaaa,.....}(奇数长度的字符串,不包括 Null)
且 L 2 ={ ε, aa, aaaa, aaaaaa,.......} (偶数长度的字符串,包括 Null)
L 1 ∪ L 2 = { ε, a, aa, aaa, aaaa, aaaaa, aaaaaa,......}
(所有可能长度的字符串,包括 Null)
RE (L 1 ∪ L 2 ) = a* (它本身就是正则表达式)
于是,证明了。
性质2. 两个正则集的交集是正则的。
证明-
让我们看两个正则表达式
RE 1 = a(a*) 且 RE 2 = (aa)*
因此,L 1 = { a,aa, aaa, aaaa, ....} (所有可能长度的字符串,不包括 Null)
L 2 = { ε, aa, aaaa, aaaaaa,.......} (偶数长度的字符串,包括 Null)
L 1 ∩ L 2 = { aa, aaaa, aaaaaa,.......} (偶数长度的字符串,不包括 Null)
RE (L 1 ∩ L 2 ) = aa(aa)* 本身就是一个正则表达式。
于是,证明了。
性质3. 正则集的补集是正则的。
证明-
让我们采用正则表达式 -
RE = (aa)*
所以,L = {ε, aa, aaaa, aaaaaa, ....} (偶数长度的字符串,包括 Null)
L的补集是L中不存在的所有字符串。
因此,L' = {a, aaa, aaaaa, .....}(奇数长度的字符串,不包括 Null)
RE (L') = a(aa)* 本身就是一个正则表达式。
于是,证明了。
性质4. 两个正则集的差值是正则的。
证明-
让我们采用两个正则表达式 -
RE 1 = a (a*) 且 RE 2 = (aa)*
因此,L 1 = {a, aa, aaa, aaaa, ....} (所有可能长度的字符串,不包括 Null)
L 2 = { ε, aa, aaaa, aaaaaa,.......} (偶数长度的字符串,包括 Null)
L 1 – L 2 = {a, aaa, aaaaa, aaaaaaa, ....}
(除 Null 之外的所有奇数长度的字符串)
RE (L 1 – L 2 ) = a (aa)* 这是一个正则表达式。
于是,证明了。
性质5. 正则集的反转是正则的。
证明-
如果L是正则集,我们必须证明L R也是正则集。
令L = {01, 10, 11, 10}
RE(左)= 01 + 10 + 11 + 10
L R = {10, 01, 11, 01}
RE (LR ) = 01 + 10 + 11 + 10 这是正则
于是,证明了。
性质6. 正则集的闭包是正则的。
证明-
如果 L = {a, aaa, aaaaa, .......} (奇数长度的字符串,不包括 Null)
即,RE (L) = a (aa)*
L* = {a, aa, aaa, aaaa , aaaaa,……………} (除 Null 之外的所有长度的字符串)
RE (L*) = a (a)*
于是,证明了。
性质7. 两个正则集的串联是正则的。
证明 -
设RE 1 = (0+1)*0 且 RE 2 = 01(0+1)*
这里,L 1 = {0, 00, 10, 000, 010, ……} (以 0 结尾的字符串集合)
且L 2 = {01, 010,011,.....} (以 01 开头的字符串集)
那么,L 1 L 2 = {001,0010,0011,0001,00010,00011,1001,10010,........................}
包含 001 作为子字符串的字符串集合,可以用 RE 表示 - (0 + 1)*001(0 + 1)*
于是,证明了。
与正则表达式相关的恒等式
给定 R、P、L、Q 作为正则表达式,以下恒等式成立 -
- ∅* = ε
- ε* = ε
- RR* = R*R
- R*R* = R*
- (R*)* = R*
- RR* = R*R
- (PQ)*P =P(QP)*
- (a+b)* = (a*b*)* = (a*+b*)* = (a+b*)* = a*(ba*)*
- R + ∅ = ∅ + R = R (并集恒等式)
- R ε = ε R = R (串联恒等式)
- ∅ L = L ∅ = ∅ (串联的零子)
- R + R = R (幂等定律)
- L(M+N)=LM+LN (左分配律)
- (M + N) L = ML + NL (右分配律)
- ε + RR* = ε + R*R = R*
阿登定理
为了找出有限自动机的正则表达式,我们使用阿登定理以及正则表达式的属性。
声明-
设P和Q为两个正则表达式。
如果P不包含空字符串,则R = Q + RP有唯一解,即R = QP*
证明-
R = Q + (Q + RP)P [输入值后R = Q + RP]
= Q + QP + RPP
当我们一次又一次递归地输入R的值时,我们得到以下等式 -
R = Q + QP + QP 2 + QP 3 ......
R = Q (ε + P + P 2 + P 3 + ….)
R = QP* [由于 P* 表示 (ε + P + P2 + P3 + ….) ]
于是,证明了。
应用雅顿定理的假设
- 转换图不得有 NULL 转换
- 它必须只有一个初始状态
方法
步骤 1 - 对于具有 n 个状态且初始状态为 q 1的 DFA 的所有状态,创建如下形式的方程。
q 1 = q 1 R 11 + q 2 R 21 + … + q n R n1 + ε
q 2 = q 1 R 12 + q 2 R 22 + … + q n R n2
…………………………
…………………………
…………………………
…………………………
q n = q 1 R 1n + q 2 R 2n + … + q n R nn
R ij表示从q i到q j 的边的标签集合,如果不存在这样的边,则R ij = ∅
步骤 2 - 求解这些方程以获得以R ij表示的最终状态方程
问题
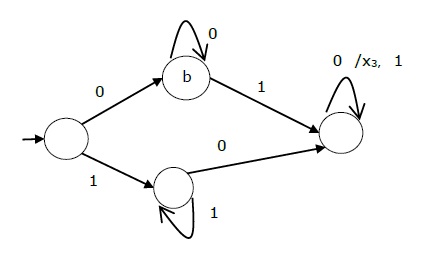
构造与下面给出的自动机相对应的正则表达式 -
解决方案-
这里的初始状态和最终状态是q 1。
三个状态 q1、q2 和 q3 的方程如下 -
q 1 = q 1 a + q 3 a + ε (ε move 是因为 q1 是初始状态0
q 2 = q 1 b + q 2 b + q 3 b
q 3 = q 2 a
现在,我们将求解这三个方程 -
q 2 = q 1 b + q 2 b + q 3 b
= q 1 b + q 2 b + (q 2 a)b (q 3的代入值)
= q 1 b + q 2 (b + ab)
= q 1 b (b + ab)* (应用阿登定理)
q 1 = q 1 a + q 3 a + ε
= q 1 a + q 2 aa + ε (q 3的代入值)
= q 1 a + q 1 b(b + ab*)aa + ε (q 2的替换值)
= q 1 (a + b(b + ab)*aa) + ε
= ε (a+ b(b + ab)*aa)*
= (a + b(b + ab)*aa)*
因此,正则表达式为 (a + b(b + ab)*aa)*。
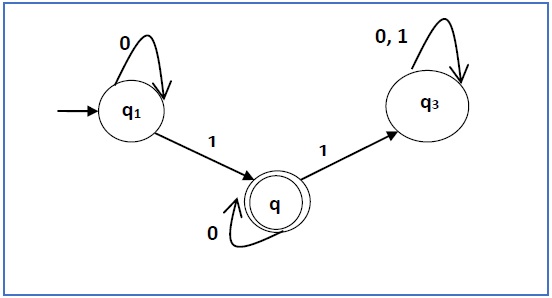
问题
构造与下面给出的自动机相对应的正则表达式 -
解决方案-
这里初始状态是 q 1,最终状态是 q 2
现在我们写下方程 -
q 1 = q 1 0 + ε
q 2 = q 1 1 + q 2 0
q 3 = q 2 1 + q 3 0 + q 3 1
现在,我们将求解这三个方程 -
q 1 = ε0* [As, εR = R]
所以,q 1 = 0*
q 2 = 0*1 + q 2 0
所以,q 2 = 0*1(0)* [根据雅顿定理]
因此,正则表达式为 0*10*。
从 RE 构建 FA
我们可以使用汤普森构造从正则表达式中找出有限自动机。我们将把正则表达式简化为最小的正则表达式,并将它们转换为 NFA,最后转换为 DFA。
一些基本的 RA 表达式如下:
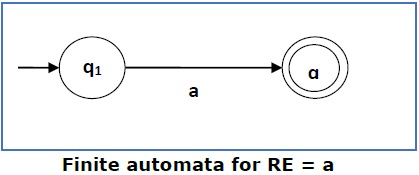
情况 1 - 对于正则表达式 'a',我们可以构造以下 FA -
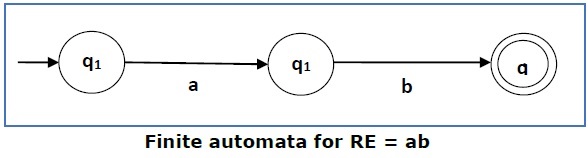
情况 2 - 对于正则表达式 'ab',我们可以构造以下 FA -
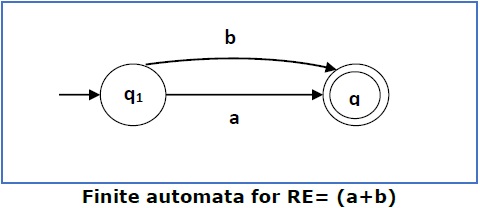
情况 3 - 对于正则表达式 (a+b),我们可以构造以下 FA -
情况 4 - 对于正则表达式 (a+b)*,我们可以构造以下 FA -
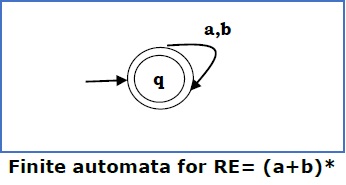
方法
步骤 1 根据给定的正则表达式构造一个带有 Null 移动的 NFA。
步骤 2 从 NFA 中删除 Null 转换,并将其转换为等效的 DFA。
问题
将以下 RA 转换为其等效的 DFA − 1 (0 + 1)* 0
解决方案
我们将连接三个表达式“1”、“(0 + 1)*”和“0”
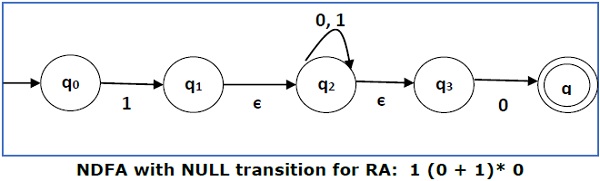
现在我们将删除ε跃迁。从 NDFA 中删除ε转换后,我们得到以下结果 -
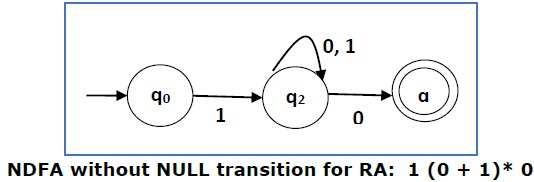
它是对应于 RE − 1 (0 + 1)* 0 的 NDFA。如果要将其转换为 DFA,只需应用第 1 章中讨论的将 NDFA 转换为 DFA 的方法即可。
具有零移动的有限自动机 (NFA-ε)
具有零移动的有限自动机 (FA-ε) 不仅在给出字母集的输入后而且在没有任何输入符号的情况下进行传输。这种没有输入的转换称为